SPSSX2检验过程.docx
《SPSSX2检验过程.docx》由会员分享,可在线阅读,更多相关《SPSSX2检验过程.docx(12页珍藏版)》请在冰点文库上搜索。
SPSSX2检验过程
X2 检验
X2检验是用途广泛的假设检验方法,它的原理是检验实际分布和理论分布的吻合程度。
在SPSS中,所有X2检验均用Crosstabs完成。
Crosstabls过程用于对计数资料和有序分类资料进行统计描述和统计推断。
在分析时可以产生二维至n维列联表,并计算相应的百分数指标。
统计推断则包括了我们常用的X2检验、Kappa值,分层X2(X2M-H)。
Crosstabs过程不能产生一维频数表(单变量频数表),该功能由Frequencies过程实现。
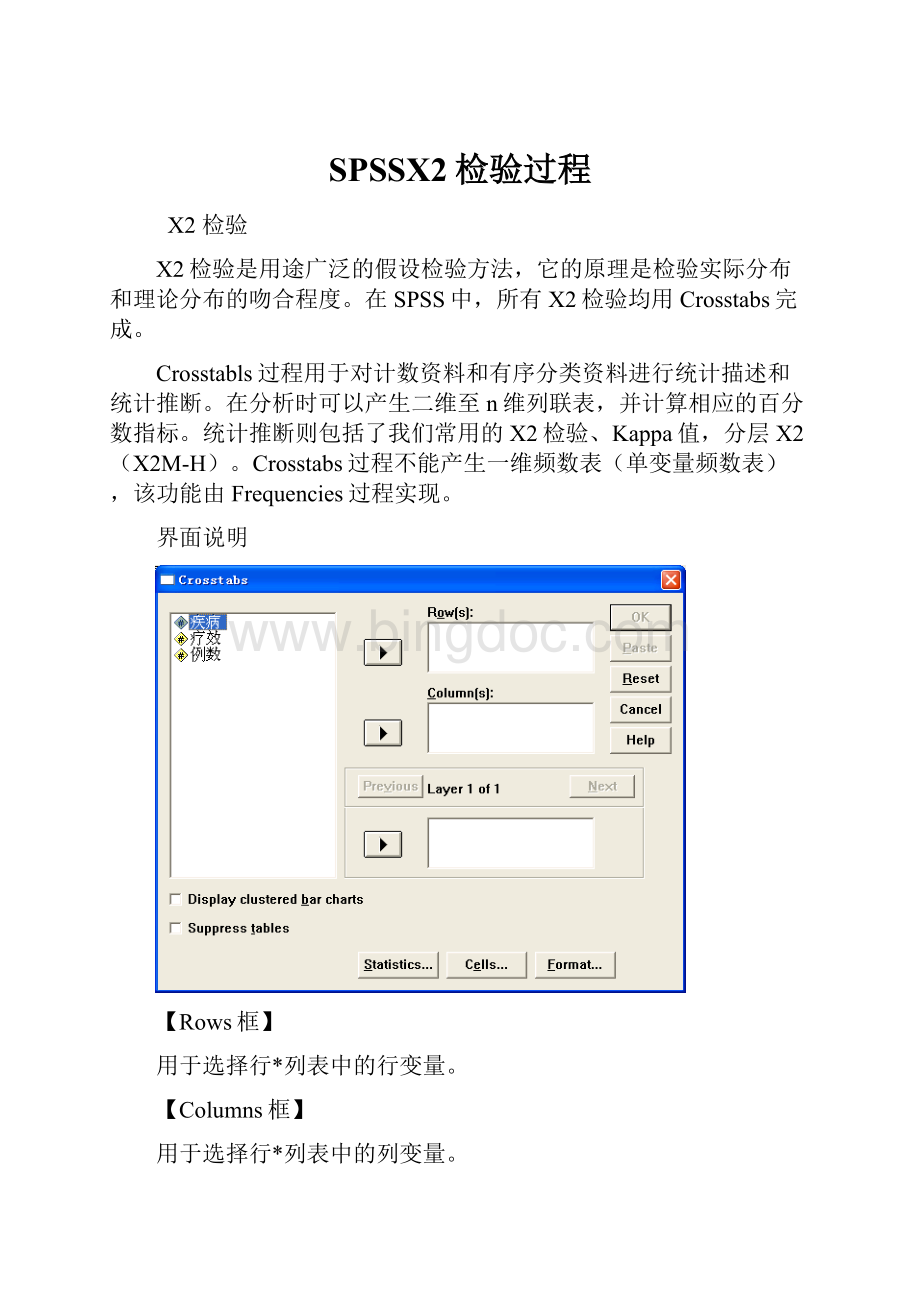
界面说明
【Rows框】
用于选择行*列表中的行变量。
【Columns框】
用于选择行*列表中的列变量。
【Layer框】
Layer指的是层,对话框中的许多设置都可以分层设定,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。
如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next钮设为不同层。
Layer在这里用的比较少,在多元回归中我们将进行详细的解释。
【Displayclusteredbarcharts复选框】
显示重叠条图。
【Suppresstable复选框】
禁止在结果中输出行*列表。
【Statistics】按钮
弹出Statistics对话框,用于定义所需计算的统计量。
Chi-square复选框:
计算X2值。
Correlations复选框:
计算行、列两变量的Pearson相关系数和Spearman等级相关系数。
Norminal复选框组:
选择是否输出反映分类资料相关性的指标,这些指标在变量为有序或无序分类时均可以使用,但有序分类变量使用Ordinal复选框组中的统计量更好。
Contingencycoefficient复选框:
即列联系数,基于X2值,其值界于0~1之间,越大表明两变量间相关性月强。
PhiandCramer'sV复选框:
这两者也是基于X2值的,Phi在四格表X2检验中界于-1~1之间,在R*C表X2检验中界于0~1之间;Cramer'sV则界于0~1之间;
Lambda复选框:
用于自变量预测应变量的效果。
其值为1时表明自变量预测应变量好,为0时表明自变量预测应变量差;
Uncertaintycoefficient复选框:
不确定系数,以熵为标准的比例缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变量,其值接近0时表明后一变量的信息与前一变量无关。
Ordinal复选框组:
计算输出反映有序分类变量一致性的指标。
Gamma复选框:
界于-1~1之间,观察值集中于对角线时,其值为1或-1,表示两者取值完全一致或完全不一致,两变量无关时该值为0。
Somers'd复选框:
为独立变量上不存在同分的偶对中,同序对子数超过异序对子数的比例;
Kendall'stau-b复选框:
界于-1~1之间;
Kendall'stau-c复选框:
界于-1~1之间;
Eta复选框:
计算Eta值,其平方值可认为是应变量受不同因素影响所致方差的比例;
Kappa复选框:
计算Kappa值,即内部一致性系数;这是医学上很常用的一致性指标,取值0-1之间。
≥0.75,一致性较好,0.4~0.75,表明一致性一般,<0.4表明一致性差。
Risk复选框:
计算比数比OR值和RR值;
McNemanr复选框:
进行McNemanr检验,即常用的配对计数资料的X2检验(一种非参检验);
Cochran'sandMantel-Haenszelstatistics复选框:
计算X2M-H统计量(分层X2,也有写为X2CMH的),可在下方输出H0假设的OR值,默认为1。
【Cells】按钮
弹出Cells对话框,用于定义列联表单元格中需要计算的指标:
Counts复选框组:
是否输出实际观察数(Observed)和理论数(Expected);
Percentages复选框组:
是否输出行百分数(Row)、列百分数(Column)以及合计百分数(Total);
Residuals复选框组:
选择残差的显示方式,可以是实际数与理论数的差值(Unstandardized)、标化后的差值(Standardized,实际数与理论数的差值除理论数),或者由标准误确立的单元格残差(Adj.Standardized);
【Format钮】
用于选择行变量是升序还是降序排列。
分析实例
一、四格表资料的X2检验
例1
组别有效无效合计有效率(%)
甲组3194077.50
乙组14264035.00
合计45358056.25
【建立数据文件】
由于此处给出的是频数表(大部分资料都以这种形式给出),因此在建立数据集时可以直接输入三个变量:
1、行变量(分组变量):
变量名取“R”,变量值为1=“甲治疗组”,2=“乙治疗组”
2、列变量(疗效变量):
变量名取“C”,变量值为1=“有效”,2=“无效”;
3、指示每个格子中频数的变量:
变量名取“F”,直接输入各个格子的频数。
所建立的数据集用WeightCases对话框指定频数变量进行加权,最后调用Crosstabs过程进行X2检验。
R
C
F
1.00
1.00
31.00
1.00
2.00
9.00
2.00
1.00
14.00
2.00
2.00
26.00
【操作过程】
Data==>WeightCases(对数据按频数进行加权)
WeightCasesby单选框:
选中
FreqencyVariable:
选入F
单击OK钮
Analyze==>DescriptiveStatistics==>Crosstabs
Rows框:
选入R
Columns框:
C
Statistics按钮:
选中Chi-square复选框,单击Continue钮
Cells...按钮:
选中Row复选框,单击Continue钮
单击OK钮
【结果解释】
上题分析结果如下:
首先是有效记录数和处理记录缺失值情况报告,可见80例均为有效值。
上表为列出的四格表,其中加入变量值和变量值标签,看起来很清楚。
上表给出了一堆检验结果,从左到右为:
检验统计量值(Value)、自由度(df)、双侧近似概率(Asymp.Sig.2-sided)、双侧精确概率(ExactSig.2-sided)、单侧精确概率(ExactSig.1-sided);从上到下为:
Pearson卡方(PearsonChi-Square即常用的卡方检验)、连续性校正的卡方值(ContinuityCorrection)、对数似然比方法计算的卡方(LikelihoodRatio)、Fisher's确切概率法(Fisher'sExactTest)、线性相关的卡方值(LinearbyLinearAssociation)、有效记录数(NofValidCases)。
另外,ContinuityCorrection和Pearson卡方值处分别标注有a和b,表格下方为相应的注解:
a.只为2*2表计算。
b.0%个格子的期望频数小于5,最小的期望频数为13.78。
因此,这里无须校正,直接采用第一行的检验结果,即X2=14.679,P=0.000。
因P=0.000,可以认为两种治疗方案疗效有差异,结合样本率,可以认为甲方案有效率高于乙方案。
二、配对计数资料X2检验
AB两种试纸检验尿葡萄糖结果
B试纸
A试纸+—合计
+702090
—4610
合计7426100
【建立数据文件】
输入三个变量:
行变量(A试纸):
变量名取“R”,变量值为1=“阳性”,2=“阴性”
列变量(B试纸):
变量名取“C”,变量值为1=“阳性”,2=“阴性”
指示每个格子中频数的变量:
变量名取“F”,直接输入各个格子的频数。
所建立的数据集如下表。
然后用WeightCases对话框指定频数变量进行加权,最后调用Crosstabs过程进行X2检验。
R
C
F
1.00
1.00
70.00
1.00
2.00
20.00
2.00
1.00
4.00
2.00
2.00
6.00
【操作过程】
1.Data==>WeightCases(对数据按频数进行加权)
WeightCasesby单选框:
选中
FreqencyVariable:
选入F
单击OK钮
2.Analyze==>DescriptiveStatistics==>Crosstabs
Rows框:
选入R
Columns框:
C
Statistics按钮:
选中Chi-square复选框(分析A、B两种试纸结果有无相关)
选中McNemanr复选框:
(做配对X2检验,分析A、B两种试纸结果阳性率有无差异)
单击Continue钮
Cells...按钮:
选中Row复选框,单击Continue钮
单击OK钮
【结果解释】
°¸Àý´¦ÀíÕªÒª
°¸Àý
ÓÐЧµÄ
ȱʧ
ºÏ¼Æ
N
°Ù·Ö±È
N
°Ù·Ö±È
N
°Ù·Ö±È
AÊÔÖ½*BÊÔÖ½
100
100.0%
0
.0%
100
100.0%
上表为有效例数,缺失例数和总例数的情况,100例均有效.
上表输出配对四格表数据。
A、B两种试纸结果阳性率有无差异)
上表为X2检验的结果。
首先是成组X2检验,X2=6.676,P=0.010,可以认为A、B两种试纸的结果有相关性(即A阳性,B可能也阳性)。
下面做了配对X2检验(McNemarTest),用精确概率法计算,P=0.002(双侧),可以认为A、B两种试纸的阳性率差异有统计学意义。
三、R×C表X2检验
这是4×2表资料,要进行4个样本率的比较。
【建立数据文件】
直接输入三个变量:
行变量(分组变量):
变量名取“R”,变量值为1=“鳞癌”,2=“腺癌”,3=“腺鳞癌”,4=“小细胞癌”。
列变量:
变量名取“C”,变量值为1=“表达”,2=“不表达”
指示每个格子中频数的变量:
变量名取“F”,直接输入各个格子的频数。
所建立的数据集如下表。
R
C
F
1
1
95
1
2
40
2
1
65
2
2
30
3
1
20
3
2
10
4
1
10
4
2
10
【操作过程】
1.Data==>WeightCases(对数据按频数进行加权)
WeightCasesby单选框:
选中
FreqencyVariable:
选入F
单击OK钮
2.Analyze==>DescriptiveStatistics==>Crosstabs
Rows框:
选入R
Columns框:
C
Statistics按钮:
选中Chi-square复选框
单击Continue钮
Cells...按钮:
选中Row复选框
单击Continue钮
单击OK钮
【结果解释】
°¸Àý´¦ÀíÕªÒª
°¸Àý
ÓÐЧµÄ
ȱʧ
ºÏ¼Æ
N
°Ù·Ö±È
N
°Ù·Ö±È
N
°Ù·Ö±È
R*C
280
100.0%
0
.0%
280
100.0%
上表为有效例数,缺失例数和总例数的情况,280例均有效。
 升级会员
升级会员 