SQLServer数据仓库与数据挖掘.pptx
《SQLServer数据仓库与数据挖掘.pptx》由会员分享,可在线阅读,更多相关《SQLServer数据仓库与数据挖掘.pptx(58页珍藏版)》请在冰点文库上搜索。
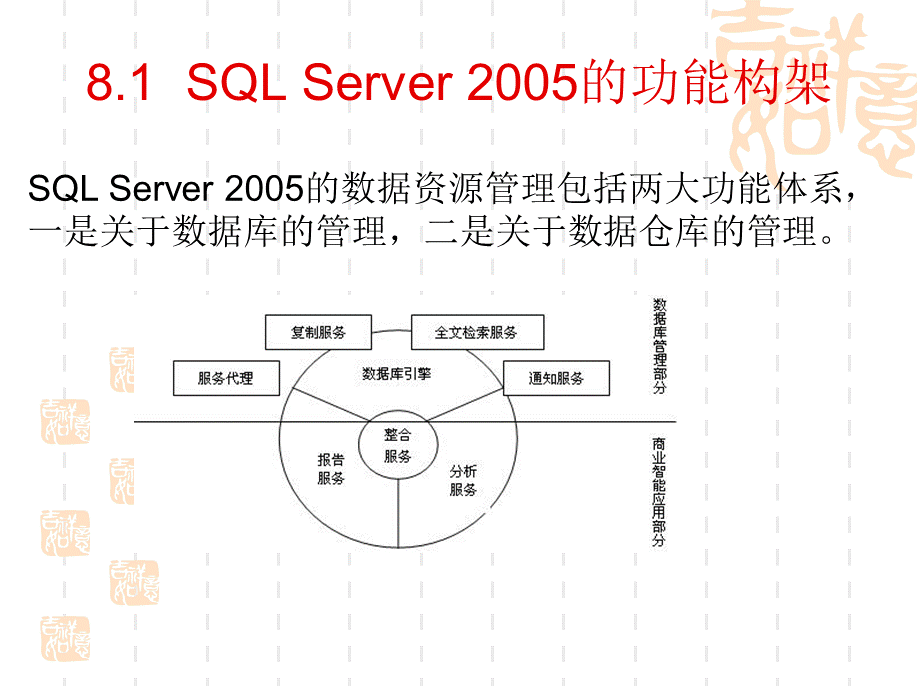
8.1SQLServer2005的功能构架,SQLServer2005的数据资源管理包括两大功能体系,一是关于数据库的管理,二是关于数据仓库的管理。
8.1SQLServer2005的功能构架,SQLServer2005在数据仓库方面提供了三大服务和一个工具来实现系统的整合。
三大服务是SQLServer2005AnalysisServices(SSAS)、SQLServer2005IntegrationServices(SSIS)SQLServer2005ReportingServices(SSRS),一个工具是BusinessIntelligenceDevelopmentStudio。
8.1SQLServer2005的功能构架,8.1SQLServer2005的功能构架,SSIS能从各种异构数据源中整合数据到数据仓库中,这项功能在以前是通过DTS服务(即数据转换服务)来实现的。
SSAS是从数据中产生知识的关键,通过这种服务,可以构建数据立方(Cube),也就是多维数据集,然后进行OLAP分析,SSAS也提供数据挖掘的功能。
SSRS是报表设计工具,通过它可以对分析结果提供类型多样、美观且适合不同需求的图表和报表。
8.3SQLServer集成服务,8.3.1SQLServer集成服务的作用在SQLServer2005IntegrationServices(SSIS)中,可以方便地创建解决方案,来执行提取、转换和加载数据(ETL)的处理。
SSIS提供了设计、创建、部署和管理包的功能,用于处理日常的业务需求。
8.3.1SQLServer集成服务的作用,建立SSIS解决方案时,创建新的项目,该项目可以放在一般的方案管理之下,但它只是逻辑的管理单位,SSIS设计、新建、访问和执行的单位依然是包(Package),包可以理解为SSIS项目中基本的部署和执行单元。
8.3.2控制流,SSIS包中的控制流由一组任务组成。
上图显示了一个简单的控制流示例。
它以FTP任务开始,该FTP任务用于下载已压缩的数据文件。
一旦下载完这些文件,运行时就会到达Foreach循环容器,在该容器内部有三个任务:
执行进程任务(该任务调用unzip应用程序来解压缩数据文件)、大容量插入任务和检查数据库完整性任务。
当解压缩完数据文件,数据文件中的数据被加载到SQLServer中并检查完数据库的完整性时,循环会停止。
如果在循环期间发生了错误,则该控制流将执行发送邮件任务:
向DBA发送电子邮件。
如果正确地执行了每个任务,则该控制流将执行SQL任务,然后更新统计信息。
8.3.3数据流,数据流是专门处理数据操作的工作流,也称为流水线。
在数据流中的每个节点都称为转换。
数据流通常以源转换开始,以目标转换结束。
上图显示了一个数据流的示例。
该数据流以OLEDBSource转换开始,该转换加载包含上市公司基本情况的事实表。
第二个转换是“查找”,该转换从上市公司基本情况表中查找上市公司简称。
这列数据被加入到流水线的数据中。
下一个转换是“条件性拆分”,该转换将“ST公司”与“正常公司”分开。
由于分析中ST公司与正常公司可比性不强,属于异常值,需要剔出,因此“ST公司”转换为Excel目标表保存即可,“正常公司”的相关数据则到达“派生列”转换,该转换根据流通A股中个人持股数量和总股本数计算“个人持股比例”,再经过“聚合”转换,按行业求算“平均个人持股比例”,最后转换为“SQLServer目标”为后期的数据挖掘做准备。
值得注意的是,在创建包以及数据流之前,需要充分了解在源数据和目标数据中使用的格式。
了解了这两种数据格式后,才能确定将源数据映射到目标数据所需的转换。
8.3.4设计和使用ETL,数据仓库的设计是数据分析和数据挖掘的基础工作,良好的数据仓库结构设计是以后工作能顺利进行的保证。
数据仓库中的数据一般要从原始业务数据中获取,经过“提取转换加载”即ETL过程,对分析有帮助的数据将保存于数据仓库中。
Step1单击“开始”菜单,选择“所有程序”,再指向MicrosoftSQLServer2005,再单击SQLServerBusinessIntelligenceDevelopmentStudio。
在“文件”菜单上,选择“新建”,再单击“项目”。
Step2在“新建项目”对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“IntegrationServices项目”,在“名称”框中,键入项目名称Stock_IS。
Step3在“项目”菜单中选择“SSIS导入和导出向导”命令,在“选择数据源”窗口中的“数据源”下拉列表框中选择Access数据源选项,如图8.6所示。
然后在路径选择中选择此项目文件夹中的stockDB.mdf文件。
8.3.4设计和使用ETL,8.3.4设计和使用ETL,Step4在选择目标窗口选择“SQLNativeClient”,如图8.7所示。
设置好服务器及其登录信息后,键入目标数据库名,也可以用系统默认的数据库名。
Step5在“指定表复制或查询”窗口,选择需要复制的数据源中的表和视图,或自定义的查询,这里选择“复制一个或多个表或视图的数据”,如图8.8所示。
Step6完成数据导入操作之前,系统将要求用户确认操作列表,并提示将会把包以“Package1.dtsx”作为文件名保存在项目文件夹下面,而且不会立即执行,确认无误后单击“完成”。
8.3.4设计和使用ETL,8.3.4设计和使用ETL,8.3.4设计和使用ETL,8.4SQLServer分析服务,8.4.1创建AnalysisServices项目Step1单击“开始”菜单,选择“所有程序”,再指向MicrosoftSQLServer2005,再单击SQLServerBusinessIntelligenceDevelopmentStudio。
Step2在VisualStudio的“文件”菜单上,选择“新建”,再单击“项目”。
Step3在“新建项目”对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“AnalysisServices项目”。
Step4将项目名称命名为STOCK_AS,这也将更改解决方案名称,然后“确定”。
8.4.1创建AnalysisServices项目,8.4.2定义数据源,Step1在解决方案资源管理器中,右键单击“数据源”,然后单击“新建数据源”,将打开数据源向导,如图8.11所示。
在“欢迎使用数据源向导”页上,单击“下一步”按钮。
Step2在“选择如何定义连接”页上,可以基于新连接、现有连接或以前定义的数据源对象来定义数据源。
以前定义的数据源对象是当前项目中或当前解决方案的其他项目中的现有数据源定义。
在本例中选择“新建”,如图8.12所示,也就是基于新连接定义新数据源。
Step3在“连接管理器”对话框中,可定义数据源的连接属性。
首先,在“提供程序”列表中,选则“本机OLEDBSQLNativeClient”选项,即可连接本机的SQLServer数据源。
Step4在数据源向导的“模拟信息”页上,可以定义AnalysisServices用于连接数据源的安全凭据。
在本例中,选择AnalysisServices服务账户,因为该账户具有访问STOCKDB数据库所需的权限。
选择“使用服务账户”,如图8.14所示,然后单击“下一步”按钮即显示随后出现的“完成向导”页。
Step5在“完成向导”页上,写出数据源的名称,本例中将数据源命名为StockDW,单击“完成”以创建名为StockDW的新数据源。
如图8.15所示解决方案资源管理器的“数据源”文件夹中可以看到的新数据源。
若要修改现有数据源的属性,可以在“数据源”文件夹中双击该数据源,并在“数据源设计器”中修改数据源属性。
8.4.3定义数据源视图,Step1在解决方案资源管理器中,右键单击“数据源视图”,再单击“新建数据源视图”,如图8.16所示。
此时将打开数据源视图向导。
Step2在数据源视图向导的“选择数据源”页,选则StockDW数据源,如图8.17所示。
单击“下一步”,将显示“选择表和视图”页。
8.4.3定义数据源视图,Step3在“选择表和视图”页中,可以从选定的数据源提供的对象列表中选择表和视图。
在“可用对象”列表中,选择需要的表,并将选中的表添加到“包含的对象”列表中。
然后,写出数据源视图的名称StockVIEW,就可以“完成”数据源视图的定义。
Step4数据源视图StockVIEW将在解决方案资源管理器的“数据源视图”文件夹中显示。
数据源视图的内容也可以在数据源视图设计器中进行修改。
图8.18显示了数据源视图设计器中的数据源视图StockVIEW。
8.4.3定义数据源视图,8.4.4用AnalysisServices创建维与多维数据集,1常规维度关系当维度的键列与事实数据表直接联接时,多维数据集维度与度量值组之间便会存在常规维度关系。
这种直接关系基于基础关系数据库中的主键-外键关系,但是也可以基于数据源视图中定义的逻辑关系。
常规维度关系表示传统星型架构设计中维度表与事实数据表之间的关系。
2引用维度关系当多维数据集维度的键列通过其他维度表中的键与事实数据表间接联接时,该维度与度量值组之间便会存在引用维度关系。
引用维度关系表示雪花型架构设计中的维度表与事实数据表之间的关系。
当雪花型架构中的各维度表进行连接时,可以使用多个表中的列定义一个维度,也可以根据单独的维度表定义单独的维度,然后使用引用维度关系设置定义这些维度之间的链接。
3事实维度关系事实维度通常称为退化维度,是通过事实数据表而非维度表中的列构造的标准维度。
有用的维度数据有时存储在事实数据表中可以减少重复。
4多对多维度关系多对多维度可将维度模型扩展了传统的星型架构范围,并在维度不直接与事实数据表相关联的情况下支持复杂分析。
Step1在解决方案资源管理器中,右键单击“多维数据集”,然后单击“新建多维数据集”。
Step2在“欢迎使用多维数据集向导”页上,单击“下一步”按钮,并在“选择生成方法”页上,确认已选中“使用数据源生成多维数据集”选项,此时,可以启用“自动生成”选项,如图8.19所示,这样多维数据集向导将自动定义维度表中各列的属性并自动生成多级层次结构。
当然,也可以手动创建属性,然后生成层次结构。
8.4.4用AnalysisServices创建维与多维数据集,Step3在“选择数据源视图”页上,确认已选中StockVIEW数据源视图。
在使用多维数据集向导生成多维数据集时,可以在“选择数据源视图”页上单击“完成”按钮,以让该向导定义多维数据集的其余属性;也可以根据需要自己定义多维数据集的其余属性。
若直接进入“完成向导”页,可以在该页为多维数据集指定名称并可以查看其结构。
本例中单击“下一步”按钮,以查看并进一步定义多维数据集的属性。
Step4向导扫描在数据源对象中定义的数据库中的表,以标识事实数据表和维度表以及与事实数据表相关的度量值,在“检测事实数据表和维度表”页上单击“下一步”按钮,将显示该向导所标识的事实数据表和维度表。
图8.20显示了该向导的“标识事实数据表和维度表”页,其中为STOCK_AS项目选择了事实数据表和维度表。
8.4.4用AnalysisServices创建维与多维数据集,Step5单击“下一步”按钮,在随即出现的“选择度量值”页中,显示了向导所选择的度量值。
在此,也可以进行修改。
一般选择事实数据表中的各数值数据类型列作为度量值,如图8.21所示。
Step6在“完成向导”页上,将多维数据集的名称更改为StockDIMS,在该页上,也可以查看多维数据集的度量值组、度量值、维度、层次结构和属性,如图8.23所示,单击“完成”按钮以完成向导。
8.4.4用AnalysisServices创建维与多维数据集,8.4.4用AnalysisServices创建维与多维数据集,8.4.4用AnalysisServices创建维与多维数据集,8.4.5部署AnalysisServices项目,Step1在解决方案资源管理器中,右键单击项目名“STOCK_AS”,然后单击“属性”选项。
将出现“STOCK_AS属性页”对话框,并显示活动配置的属性。
在此可以定义多个配置,每个配置可以具有不同的属性。
Step2在“STOCK_AS属性页”的树型目录里选择“部署”选项,并在“目标”区域的“服务器”文本框里输入AnalysisServices服务器名及实例名,若省略实例名则部署到默认实例,然后“确定”,如图8.25所示,以完成配置属性的设置。
8.4.5部署AnalysisServices项目,8.4.5部署AnalysisServices项目,Step3在解决方案资源管理器中,右键单击项目名“STOCK_AS”,再单击“部署”选项,或者在“生成”菜单上单击“部署STOCK_AS”,就可以在“部署进度”对话框中看到部署情况。
Step4单击“视图”菜单栏中的“输出”选项,可以查看部署是否成功。
部署完STOCK_AS项目之后,启动SQLServerManagementStudio,在“连接到服务器”对话框里的“服务器类型”下拉列表框里选择“AnalysisServices”选项并写出部署的服务器名和实例名。
连接后,在SQLServerManagementStudio的“对象资源管理器”里,就可以看到部署的项目。
8.4.5部署AnalysisServices项目,利用数据挖掘向导可以创建挖掘结构和挖掘模型,使用该向导可以定义结构并制定创建基于该结构的初始模型时使用的算法和定型数据。
具体过程包括:
选择数据源类型,选择算法,选择数据源并且指定数据源表的用法,选择表中的列并且指定这些列的用法,对挖掘模型命名。
接下来,可以对模型进行处理和分析,还可以生成数据挖掘报表。
Step1在解决方案资源管理器中,选择“挖掘结构”,单击右键,在弹出的菜单中选择“新建挖掘结构”命令,弹出“数据挖掘向导”对话框,单击“下一步”按钮。
Step2“选择定义方法”对话框中,需要开发人员选择创建模型的源是来自于一个关系源还是来自于多维源,虽然最后创建的结果相同,但是创建的过程不同,所以对于不同的选项有不同的向导过程。
本例中,选择“从现有关系数据库或数据仓库”。
Step3在弹出的“选择数据挖掘技术”对话框中,选择将要使用的数据挖掘技术。
算法的列表是由目标服务器的功能决定的,要选择什么算法主要取决于具体的挖掘主题。
数据挖掘模型还可以用数据挖掘扩展(DMX)语言创建和处理。
本例中选择了聚类分析和神经网络。
Step4确定将要进行挖掘的数据,即选择数据源。
本例中选择了前面已经创建好的数据源StockDW。
Step5指定表类型,确定表中各列的用法。
当选择表时,必须指定每一个表是事例表还是嵌套表,事例表包含想要分析的实体的事例,嵌套表包含每一事例附加的信息(通常是事务信息)。
Step6为挖掘结构和挖掘模型命名,如果所选择的算法支持,还可以启用钻取功能,完成向导。
使用该向导创建了数据挖掘对象之后,就可以在数据挖掘设计器中浏览并细化数据挖掘向导创建的结果。
8.6SQLServer报表服务,8.6.1创建报表报表是数据挖掘结果的归纳与呈现,可以使用自定义的方式来创建,也可以使用报表向导来创建。
Step1单击“开始”菜单,选择“所有程序”,再指向MicrosoftSQLServer2005,再单击SQLServerBusinessIntelligenceDevelopmentStudio。
在VisualStudio的“文件”菜单上,选择“新建”,再单击“项目”。
Step2在“新建项目”对话框中,从“项目类型”窗格中选择“商业智能项目”,再在“模板”窗格中选择“报表服务器项目向导”。
将项目名称命名为STOCK_RS,然后单击“确定”按钮,如图8.28所示。
8.6.1创建报表,8.6.1创建报表,Step3“选择数据源”窗口,为报表选择或创建所需数据的来源,输入数据源名称STOCKDW,选择AnalysisServices作为数据连接的类型,再单击“编辑”按钮,设置此数据源的连接属性,可以通过单击“测试连接”按钮确认此连接的正确性,然后单击“确定”按钮,如图8.29所示。
Step4在“设计查询”窗口中单击“查询生成器”,在查询生成器窗口设计希望显示在报表中的数据内容。
如图8.30所示。
Step5设计好报表要展现的内容之后要选择报表类型,在此选择了表格格式的报表类型。
如图8.31所示。
Step6设计表中数据的分组方式,针对本案例分组方式设计为先按照所在地区分页面,然后按照所属一级行业分组,每组中显示详细信息。
如图8.32所示。
Step7选择表的布局,在本例中选择了阶梯型布局,如图8.33所示。
如果希望报表列出分组小计以及明细信息,可以在复选框中选择“包括小计”和“启用明细”。
Step8选择表的样式,可以根据对话框中显示的效果选取合适的样式,在本例中选择了“正式”型,如图8.34所示,然后完成报表向导。
8.6.2使用报表,报表创建好后,就可以打开报表。
单击报表设计器上的“预览”标签,系统将从指定的报表数据源获取数据并且按照设计的报表数据布局方式显示出来,图8.35所示即为以上设计的报表的显示结果。
8.6.2使用报表,8.6.2使用报表,此报表还可以导出其他格式文件,以方便使用,单击“预览”选项卡下工具条上的保存按钮或在预览的内容中单击右键,系统允许将报表保存为6种格式的文件,这里选择Excel文件,在保存对话框中输入文件名和保存的位置,然后确定即可。
用Excel2003打开保存的文件,可以看到如图8.36所示的报表效果。
8.6.2使用报表,本章小结,在本章中,介绍了创建数据仓库和进行数据挖掘的工具MicrosoftSQLServer2005,通过SSIS能从各种异构数据源中整合BI需要的业务数据;通过SSAS可以构建多维数据集,然后进行OLAP分析以及数据挖掘;通过SSRS可以对分析结果提供类型多样、美观且适合不同需求的图表和报表。
本章的重点是阐述SQLServer数据仓库设计思路和方法,数据挖掘模型的选取策略是本章的难点所在。
 升级会员
升级会员 