SPSS统计分析SPSS数据文件的建立和整理.ppt
《SPSS统计分析SPSS数据文件的建立和整理.ppt》由会员分享,可在线阅读,更多相关《SPSS统计分析SPSS数据文件的建立和整理.ppt(56页珍藏版)》请在冰点文库上搜索。
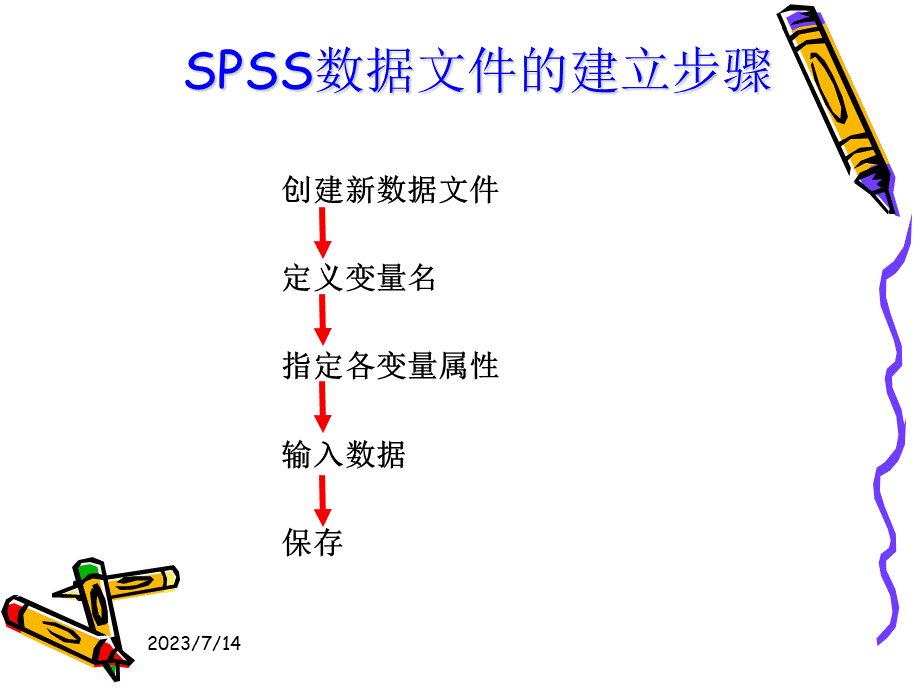
2023/7/14,SPSS数据文件的建立步骤,2023/7/14,一、变量类型与测量尺度变量类型:
数值型和字符型数值型:
如分数、收入、销售额等字符型:
如血型、性别等Tips:
SPSS默认的是数值型,2023/7/14,变量类型vs测量尺度例:
“性别”变量:
1男,2女“成绩等级”变量:
1最高,2中等,3最低Question:
“1”在不同变量中意义有何不同?
2023/7/14,测量尺度:
数据的测量尺度表现为:
定类尺度定序尺度定距尺度定比尺度计量水平由低级到高级,2023/7/14,一般来说,数据的等级越高,应用范围越广泛,等级越低,应用范围越受限。
不同测度级别的数据,应用范围不同。
等级高的数据,可以兼有等级低的数据的功能,而等级低的数据,不能兼有等级高的数据的功能。
2023/7/14,二、定义新变量(进入变量编辑窗口),名称:
名称长度控制在8位以内,并尽量使用英文名称。
类型:
宽度:
小数:
标签:
对变量进行解释值:
可简化数据录入例:
性别1男2女缺失:
缺失值的处理方法,多用于严格的大型调查列:
对齐:
测量:
变量的测量尺度,2023/7/14,二、定义新变量,练习题:
ID城市北京广州上海深圳武汉性别男女文化程度大专及以下大专本科硕士研究生硕士研究生以上职位等级一般员工基层管理者中层管理者高层管理者企业规模小型(50人以下)中型(50-200人)大型(200人以上)企业性质国企机关事业单位外资合资年总收入月基本工资1月-12月份加班工资1月-12月奖金,虚拟100人,随机数据的产生(RAND),2023/7/14,Problems:
名称:
尽可能用英文变量类型:
字符or数值型,宽度,小数点模拟数据的合理性数据检查无数据vs缺失值变量命名必须唯一,不能有两个相同的变量名,SPSS数据文件的建立,1、数据的输入2、数据的检查3、数据整理,SPSS数据文件的建立,1、数据的输入(进入数据编辑的数据窗口dataview)在SPSS中直接输入从外部文件导入
(1)Excel(.xls):
菜单:
fileopendata选择.xls文件类型直接从excel中copy,paste到spssTips:
简单但不智能,如变量名空缺,字符型变量缺失
(2)文本文档(.txt)菜单:
fileReadtextdata,2023/7/14,Exercise,1、导入SPSS自带的demo.xls文件,导入时只要包含demo中的前三个变量2、导入SPSS自带的demo.txt文件Tips:
C:
ProgramFilesSPSStutorialsample_filesdemo(.xls/.txt),2023/7/14,Problems:
名称:
尽可能用英文变量类型:
字符or数值型,宽度,小数点模拟数据的合理性数据检查无数据vs缺失值,2023/7/14,三、数据的录入和修改,(进入数据编辑的数据窗口dataview)1.在SPSS中直接录入Tips:
使用键盘而非鼠标进行操作,2023/7/14,三、数据的录入和修改,2.从外部文件导入
(1)Excel(.xls):
菜单:
fileopendata选择.xls文件类型直接从excel中copy,paste到spssTips:
简单但不智能,如变量名空缺,字符型变量缺失
(2)文本文档(.txt)菜单:
fileReadtextdata,2023/7/14,第一步:
“你的文本文件和预定义格式是否相一致”,2023/7/14,第二步:
“变量如何排列”?
“变量名包括在文件最前面么?
”,2023/7/14,第三步:
“第一条记录从第几行开始”“你的记录是怎样存储在文件中的?
”“你想导入多少条记录?
”,2023/7/14,第四步:
“变量间用的是哪种分隔符?
”,2023/7/14,第五步:
“定义在数据预览窗口中所选择的变量。
”,2023/7/14,第六步:
“你愿意保存这次的文件(读入)格式设置以备下次使用吗?
”“你是否愿意将以上操作粘贴为SPSS语句?
”,2023/7/14,Exercise,1、导入SPSS自带的demo.xls文件,导入时只要包含demo中的前三个变量2、导入SPSS自带的demo.txt文件Tips:
C:
ProgramFilesSPSStutorialsample_filesdemo(.xls/.txt),2023/7/14,三、数据的录入和修改,数据必须输入正确才能保证正确的分析结果。
但很难一次输入正确,所以就需要进行修改,一般包括数据的插入、删除、修改等。
2023/7/14,三、数据的录入和修改,找到单元格-重新输入数据查找办法:
1、移动指针到指定序号的观测值DataGotoCase2、查找指定变量中的指定数据(定位到单元格)Edit+Find(或工具栏上的Find图标按钮),2023/7/14,三、数据的录入和修改,插入一个变量在现存变量的右边:
直接在VariableView中定义在现存变量的中间:
DataView或VariableView点击右键“insertvariables”菜单:
DataInsertVariableTips:
所添加的变量都在现存变量前一个位置删除一个变量DataView选中一列数据,右键clearVariableView选中一变量名,右键clear,2023/7/14,三、数据的录入和修改,插入一个观测值在最后:
直接输入在中间:
DataInsertCasesTips:
结果是直接插入一空白行删除一个观测值选中观测量序号,后按Del,或右键clear批量数据调整选中一列数据,鼠标右键cut,copy,pasteExercise:
数据的录入和修改,2023/7/14,数据文件的管理SPSS的一个重要功能,File,Data,Transform三大菜单,2023/7/14,数据文件的管理之File菜单详解,一、新建数据文件(略)二、导入外部数据(重点)三、保存数据文件Save保存为同一数据文件Saveas保存为不同数据文件,或者只保存文件中的部分变量ExampleinSPSS,2023/7/14,四、File菜单中的其他条目DisplayDataInfo系统会在结果窗口中显示所选数据文件的详细情况,包括建立时间、标签设置、变量设置等信息GiveExampleCacheData缓冲区加快处理速度,用于处理远程数据Print和Printview打印和打印预览,2023/7/14,数据文件的管理之Utilities菜单详解,一、UtilitiesVariables菜单项:
该菜单项用于显示各个变量的基本信息注:
与FILE菜单中的DisplayDataInfo有所不同,前者单独显示各个变量的信息,后者显示整个文件的信息Giveexample二、UtilitiesFileinfo菜单项:
Thinking:
比较File菜单中的displaydatainfo与Utilities菜单中的variables以及Displaydatainfo三者功能有何不同?
2023/7/14,数据文件的管理之Utilities菜单详解,三、UtilitiesDefineSets:
定义变量集用途:
当数据文件中涉及到大量的变量,而我们所做的统计分析仅用到文件中的某几个变量时常常需要定义变量集,即将所要用到的变量定义成一个集合。
Exercise:
定义工资表中的变量集,2023/7/14,数据文件的管理之Data菜单详解,【SortCases对话框】用途:
将数据按照某一变量或某几个变量进行排序GiveExample,2023/7/14,数据文件的管理之Data菜单详解,【Transpose对话框】对数据进行行列转置原文件中的一行数据变为新文件中的一列数据,反之亦然可以在原数据文件中指定一个变量记录转置后的变量名GiveExample:
性别为新变量名,将第一季度奖金进行转置,2023/7/14,数据文件的管理之Data菜单详解,【MergeFiles对话框】Addcases从外部数据文件中增加记录(仅观测值)到当前数据文件中,称为纵向合并两文件需具有相同的变量GiveExampleAddvariables从外部数据文件增加变量到当前数据文件,称为横向合并GiveExample,2023/7/14,ExerciseData,1:
以文化程度(升)和职业等级(降)将工资表排序Tips:
注意当两个变量的排序相反时,SPSS如何处理?
2:
以城市类型为新变量名,将工人全年加班费(12个变量)进行行列转置Tips:
注意转换后文件的变量名,2023/7/14,ExerciseData,3:
新建一个数据文件,其中含有“城市”和“地区”两个变量,每个变量有10个观测值(数值为随机数),然后将新文件的“城市”变量中所有观测值合并到“工资表”中4:
新建一个数据文件,其中含有“id”和“area”两个变量。
其中id变量的数值为100110,area变量的数值为随机数。
然后以id为keyvariable将新数据文件中的“area”变量合并到“工资表”中Tips:
注意有无keyvariable的结果差异,2023/7/14,数据文件的管理之Data菜单详解,【Aggregate对话框】用于对数据进行分类汇总即按指定的分类变量对观测值进行分组,对每组记录的各变量值求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件。
2023/7/14,BreakVariables:
用于选择分组变量;AggregateVariables框:
用于选择被汇总的变量;Name&Label钮:
用于定义新产生的汇总变量的名称和标签Function钮:
用于定义汇总函数SaveNumberofcasesinbreakgroupasvariable复选框:
用于定义一个新变量以存储同组的记录数;Createnewdatafile单选钮:
定义一个新文件以存储汇总结果Replaceworkingdatafile单选钮:
用汇总的结果替换原来的数据,2023/7/14,Aggregate对话框提供的函数形式:
GiveExample:
不同城市工人的平均年总收入,求数值概况求特殊值求观测值数求百分比求百分数,2023/7/14,数据文件的管理之Data菜单详解,【SplitFile对话框】用于将数据文件分组为进一步处理做准备Analyzeallcases单选框:
选中本框不拆分文件;Comparegroups单选框:
结果紧挨在一起便于相互比较;Organizeoutputbygroups单选框:
各组分析结果单独放置;Groupsbasedon框:
用于选择拆分数据文件的变量;Sortthefilebygroupingvariables单选框:
将数据按所用的拆分变量排序;Fileisalreadysorted单选框:
数据保持原状,不按所用的拆分变量排序。
GiveExample:
根据文化程度对工资表进行拆分,2023/7/14,数据文件的管理之Data菜单详解,【SelectCases对话框】当不需要分析全部数据,而是按某种要求分析其中的一部分时使用例如:
数据库中包括全省所有学生高考语文成绩。
由于数据量太大,现在我们想只选取数据库中前5000个学生的成绩进行统计,以得到一个粗略的估计。
2023/7/14,Allcases:
分析所有的记录;Ifconditionissatisfied:
只分析满足条件的记录;Randomsampleofcases:
从原数据中按某种条件抽样;Basedontimeorcaserange:
基于记录序号来选择记录;Usefiltervariable:
使用筛选指示变量来选择记录,该变量取值为非0的记录将被选中Filtered:
未被选中的记录只是被隔离Deleted:
未被选中的记录将被删除,一般不要使用。
2023/7/14,ExerciseData,5:
计算工资表中不同性别的一月份平均加班费和一月份加班费总值6:
只选取观测值中男性的数据,再计算不同性别的一月份加班费总值Tips:
注意观察最后的结果与练习4最后的结果有何差异?
2023/7/14,数据文件的管理之Transform菜单详解,Transform:
主要针对数据中变量的变换,如根据已知变量产生一个新的变量Data:
主要针对数据库的维护,如数据文件的合并、拆分、汇总等。
2023/7/14,Transform菜单,Compute:
计算一个新变量Count:
计数,比如60分以下有几人Recode:
变量数值重新编码,比如考试分数转为及格或不及格Categorize:
归类Rankcase:
对调查对象进行排序,如对考分进行排名Automaticrecode:
自动编码Createtimeseries:
创造时间系列Replacemissingvaluve:
缺失数据替代(用某一个数字),2023/7/14,1、【Compute对话框】最常用,2023/7/14,Compute菜单中的函数介绍:
1、Arithmetic函数数学函数Abs(?
)返回变量的绝对值Arsin(?
)返回变量的反三角函数值Rnd(?
)返回数值表达式四舍五入后得到的整数值Trunc(?
)返回数值表达式截尾以后得到的整数值,2023/7/14,Compute菜单中的函数介绍:
2、Randomnumbers随机变量函数RV.Normal(mean,stddev)返回来自指定均值和标准离差的正态分布的随机数RV.EXP(shape)返回服从指定参数的指数分布随机数RV.Possion(mean)返回服从指定均值的泊松分布的随机数RV.Uniform(min,max)返回指定最小值和最大值的均匀分布的随机数Eg:
如有100个case,想打乱它们的顺序,该如何解决?
方法:
首先产生一个均匀分布的随机数,然后按随机数进行排序后即可。
2023/7/14,Compute菜单中的函数介绍:
3、统计函数CFVAR(标准离差/均值)MAX/最大值MIN/最小值MEAN/均值SD/标准差SUM/求和VARIANCE/方差,2023/7/14,Compute菜单中的函数介绍:
4、日期和时间函数Eg:
Date5、逻辑函数Eg:
ANY6、字符串函数Eg:
String7、转换函数converse主要用于字符型变量与数值型变量的转换,2023/7/14,Demo:
1、将“职位等级”由一般员工基层管理者中层管理者高层管理者这四个等级改变为一般员工基层管理者中高层管理者三个等级2、计算所有工人的第一月总收入,命名为sum_Jan3、计算前五十名工人第一季度的月平均奖金,命名为mean_bon4、将广州市工人的年总收入值增加10000,2023/7/14,计数用于标示某个值或某些值在某个变量的取值中是否出现。
SPSS会自动用数字1来标注满足所需条件的记录。
例:
如果想知道月基本工资在1000元以下的记录注意:
千万注意,Count对话框有一个潜在的bug,当需要计算同时满足两个变量取值条件的记录数有多少时,直接用该对话框会得出完全错误的结果。
2、【Count对话框】,Eg:
如果想知道月基本工资在1000元以下的北京工人有哪些记录?
2023/7/14,3、【Recode对话框】,对变量值重新编码可以将新值赋给原变量也可以生成一个新变量。
例:
将文化程度由原来的5个等级缩减为3个等级,其中大专和大专以下合并为一个,研究生及研究生以上合并为一个
(1)由一个新的变量标识
(2)直接修改原变量操作:
Transform=Record=IntoDifferentVariables(IntoSameVariables),2023/7/14,4【CategorizeVariables】,用于将连续性变量自动按要求分成等间距的几类非常简单例:
将年总收入平均分为5个等级,2023/7/14,5、【RankCases对话框】,变量编秩按照某个变量的大小对记录进行排序在非参数统计中,经常要用到秩次选项:
RankTypesTies例:
我们如果想知道这次考试中,男生数学成绩的排序和女生数学成绩的排序,就需要根据性别分组计算数学成绩的秩次,2023/7/14,6、【AutomaticRecode】,该对话框用于按原变量值的大小生成新变量,变量值就是原值的大小次序功能和RankCases对话框重复,2023/7/14,ExerciseTransform,计算文化程度在本科以上的北京高层管理者其每月的平均收入和第三季度的平均奖金,分别用变量名Mean_inc和Mean_bon来表示表示出职位等级在基层与中层之间的工人记录北京市工人的性别变量输入错误,原有的1事实上女性,而原有的2事实上是男性,所以需要进行替换计算上海和广州工人的上半年月平均工资,命名为Mean_ShG,并将月平均工资平均分为3个等级,
 升级会员
升级会员 