计算机二级VFP重点复习资料.docx
《计算机二级VFP重点复习资料.docx》由会员分享,可在线阅读,更多相关《计算机二级VFP重点复习资料.docx(37页珍藏版)》请在冰点文库上搜索。
计算机二级VFP重点复习资料
计算机二级复习资料
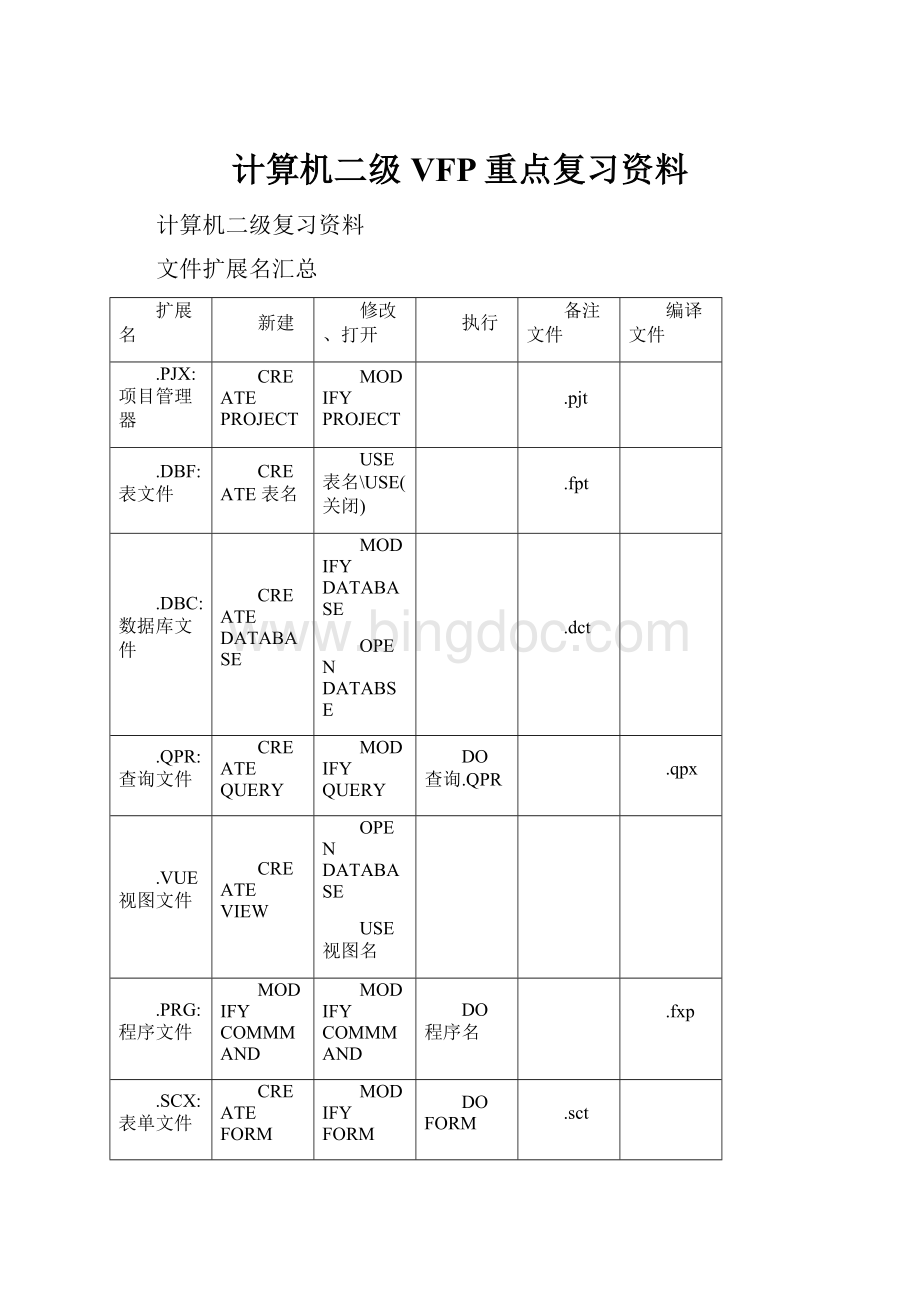
文件扩展名汇总
扩展名
新建
修改、打开
执行
备注文件
编译文件
.PJX:
项目管理器
CREATEPROJECT
MODIFYPROJECT
.pjt
.DBF:
表文件
CREATE表名
USE表名\USE(关闭)
.fpt
.DBC:
数据库文件
CREATEDATABASE
MODIFYDATABASE
OPENDATABSE
.dct
.QPR:
查询文件
CREATEQUERY
MODIFYQUERY
DO查询.QPR
.qpx
.VUE视图文件
CREATEVIEW
OPENDATABASE
USE视图名
.PRG:
程序文件
MODIFYCOMMMAND
MODIFYCOMMMAND
DO程序名
.fxp
.SCX:
表单文件
CREATEFORM
MODIFYFORM
DOFORM
.sct
.MNX:
菜单文件
CREATEMENU
MODIFYMENU
.mnt
.MPR:
菜单程序
由.MNX生成
DO菜单.MPR
.mpx
.FRX:
报表文件
CREATEREPORT
MODIFYREPORT
.frt
变量文件 .mem
可执行文件 .exe 生成的应用程序 .app
复合索引文件 .cdx 单一索引文件 .idx
控件与数据源
不同的控件有不同的数据源
一般的只具有:
controlsource
combo与list:
还有rowsource,忽略controlsource
gird:
只有它有recordsource
command:
没有数据源
第一章
理论部分
1、数据库中的数据按一定的数据模型组织、描述和存取,具有较小的冗余度、较高的数据独立性和以扩展性,并可以供多个用户和多类应用所共享。
2、关系数据库中的完整性包括域完整性(属性的取值范围)、实体完整性(任一元组主关键字不为空,且在所属的关系中唯一)和参照完整性(当一个元组的主关键字的值不为空时,以该外部关键字的值作为主关键字的值的元组必须在相应的关系中)。
3、数据库与人工智能技术相结合形成演绎数据库,与分布式处理技术相结合形成分布式数据库,与并行处理技术相结合形成并行数据库,与多媒体技术相结合形成多媒体数据库。
4、数据库系统结构的外部层、概念层和内部层分别对应于数据库模式的外模式、模式和内模式。
外部层是数据库的外部视图内部层是数据库的内部视图或存储视图,概念层是数据库的概念视图。
5、数据字典(DD)是系统中各类数据定义和描述的集合。
数据字典一般包括六个方面的内容:
外部实体、数据流、处理逻辑、数据存储、数据元素和数据结构。
6、关系的基本运算包括传统的集合运算即并、交、差和专门运算即选择、投影、联接。
7、再生成关系模型时一定要将关系规范化,关系规范化的过程是通过关系中属性的分解和关系模式的分解来实现的,一般要求3NF(第三范式)。
8、二维表中行的顺序、列的顺序可以任意交换。
9、E-R模型的图形表示法:
用矩形框表示实体集,菱形框表示联系,椭圆框表示属性。
10、数据库的核心是数据模型,数据模型有层次模型、网络模型、关系模型和面向对象模型。
目前流行的DBMS产品中,数据结构模型主要采用关系模型和面向对象的关系模型。
11、关系模型是用二维表格的结构形式来表示实体及实体间的联系
12、大型DBMS:
Oracle、DB2、Sybase、SQLServer
微机DBMS:
Access,VisualFoxPro
13、SQL:
StructuredQueryLanguage结构化查询语句
14、数据的逻辑独立性是通过外部层与概念层之间的映射来实现的,物理独立性是通过概念层与内部层之间的映射来实现的。
15、在数据世界中可以用记录(元组)来描述观念世界中的实体,用字段来描述观念世界中的实体属性。
16、数据模型是数据库系统中用与数据表示和操作的一组概念和定义。
数据模型通常有三部分组成:
数据结构、数据操作和数据的完整性约束条件。
17、数据库系统包括:
数据库、数据库管理系统、应用程序、用户和计算机支持系统。
18、对信息系统进行测试,一般包括以下三种:
模块测试、系统测试、验收测试。
19、关系模型通过二维表表示实体集,通过外部关键字表示实体间的联系。
20、关系模型的缺点:
数据冗余度大、更新异常、插入异常、删除异常。
原因:
数据之间存在依赖关系
解决的方法:
将关系规范化(即将关系分解)
21、SQL包括了所有对数据库的操作:
数据定义、数据查询、数据更新、SQL视图
22、数据库设计步骤:
系统规划、系统分析、系统设计、系统实施、系统维护。
23、SA:
Structuredanalysis结构化分析。
SA方法从最上层的组织机构入手,采用自顶向下逐层分解的方法分析系统,并采用形式化或半形式化的描述来表达数据和处理过程的关系。
常用的描述工具有数据流程图(DFD)和数据字典。
24、系统设计分为三个阶段:
概念结构设计、逻辑结构设计、物理结构设计。
25、系统的运行和维护:
(1)日常维护:
备份和回恢复、安全维护、存储空间管理、并发控制、为题解决。
(2)监控和分析:
收集统计数据、分析操作。
(3)扩展和增强:
增强应用程序、模式修改、DBMS版升级。
(4)性能调整:
调整索引、调整查询、调整事物。
26、数据流程图是使用直观的图形符号来描述系统业务过程、信息流和数据要求的工具,可以比较准确地表达数据和处理的关系。
27、关键字种类:
超关键字、候选关键字、主关键字、外部关键字。
超关键字、候选关键字、主关键字能唯一确定一条记录,外部关键字不能唯一确定一条记录。
28、项目管理器是VFP的控制中心。
同一个文件可以同时属于多个项目;可以从项目管理中把文件移去或删除;项目中文件的包含与排除。
29、在关系模型中,同一个关系中的不同属性,其属性名不可以相同。
操作部分
VFP的操作环境和项目管理器的使用
要求:
命令窗口的使用,选项对话框的使用,创建项目文件,利用项目管理器管理文件
1、换行:
?
不换行:
?
?
清屏:
clear注释:
*退出VFP:
quit
2、在D盘根目录下创建LX文件夹:
mdd:
\lx
3、将文件ex1.doc复制到D:
\lx文件夹:
copyfileex1.doctoD:
\lx
4、显示D盘Lx文件夹中所有文件的目录:
dird:
\lx\*.*
5、删除D盘LX文件夹中的文件ex1.doc:
deletefileex1.doc
第二章
1、在VFP中,一共有十一种数据类型:
字符型c(<=254)、数值型n(内存占8字节,表中占1~20字节)、货币型y(8)、浮点型f(大小同数值型)、双精度型b(8)、整型I(4)、日期型t(8)、日期时间型d(8)、逻辑型L
(1)、备注型m(4)、通用型g(4)。
2、VFP可以使用常量、变量、数组、记录和对象来存储数据。
这些称为存储数据的容器,简称数据容器。
3、名称命名规则:
名称中只能包含字母、下划线“_”、数字符号和汉字符号;名称的开头只能是字母、汉字或下划线,不能是数字;除了自由表的字段名、表的索引标识名至多只能有10个字符外,其余可以是1-128个字符;应避免使用系统保留字。
在变量命名时,最多可以有254个字符。
4、若变量与字段同名,则字段名优先,若非要使用变量,则引用:
m.x或m->x
5、内存变量的保存SAVETOfilename
内存变量的恢复RESTOREFROMfilename
6、VFP最多可声明二维数组,下标从1开始。
数组被声明后,赋予默认值.F.
7、函数接收一个或多个参数而返回单个值,因此函数可以嵌入一个表达式中。
8、用于处理数值型数据,返回值也是数值型数据。
1)ABS():
求绝对值
2)MAX():
求最大值
3)MIN():
求最小值
4)INT():
取整若int(x/2)=x/2,则X为偶数。
5)MOD():
取模
6)ROUND():
四舍五入
7)SQRT():
求平方根
8)RAND():
获得0—1之间的随机数
9、用于处理字符型数据。
1)删除前后空格ALLTRIM()删除后缀空格TRIM()
删除前缀空格LTRIM()删除后缀空格RTRIM()
2)返回一个字符串首次出现的位置区分大小写AT()不区分大小写ATC()3)LEN()
4)返回子字符串SUBSTR()
5)LEFT()RIGHT()
6)SPACE()’你’+space
(1)+’好’——你好
10、用于处理日期/时间类型的数据。
1)取系统日期DATE()取系统时间TIME()
取系统日期和时间DATETIME()
2)YEAR()取一个日期的月份MONTH()
取一个月的第几天DAY()?
DAY({^2010/07/25})——25
3)返回该日期是一周中的第几天(第一天为星期日)DOW()
11、数据类型转换函数
1)ASC():
字符→ASCII?
asc('jdhfhj')——106
2)CHR():
ASCII←字符?
CHR(66)——B
3)VAL():
C→N
4)STR():
N←C
?
str(314.15)——314没有指定宽度和小数位数,默认宽度为10
?
str(314.15,5)——‘314‘宽度为5,没有指定小数位数,前导两个空格’
?
str(314.15,5,2)——314.1宽度不够首先保整数部分
?
str(314.15,2)——***宽度为2,小于整数部分宽度,溢出
?
str(1234567890123)——1.234E+12
?
len(str(12345678901)的返回值为10
5)DTOC():
D→C
6)CTOD():
C←D
12、其他常用函数
Between()type()iif()mesagebox()-返回是值型
13、运算顺序由高到低:
()**或^、*、%、+
14、字符“+”相当于字符相连,字符“-”是将左侧字符串的尾部空格移到相连后的字符串的右侧。
$,左侧字符串包含在右侧字符串中,结果为.T.,否则为.F.
字符运算符的运算顺序由高到低为:
+、—、$
15、两个日期不能相加,但两个日期可以相减,结果是这两个日期相差的天数对日期时间型数据同样适用。
16、关系运算符:
<、>、<=、>=、=、==。
两边的操作数据的数据类型必须相同,运算的结果是逻辑型
17、对于字符型数据的比较:
1)、字符序列的设置:
(从小到大)
Machine—按机内码顺序。
(空格、大写字母、小写字母、一级汉字、二级汉字)?
”A”>“a”?
”John”<“Rose”?
“助教”<“讲师”
PinYin—汉字按拼音序列。
(系统默认的字符序列)(西文:
空格、大写字母、小写字母;汉字:
汉字按拼音顺序)
Stroke—汉字按书写的笔画的多少。
(西文:
空格、小写字母、大写字母;汉字:
汉字按笔画多少)?
“讲师”<“教授”
2)、比较字符串时,系统对两个字符串的字符从左向右逐个比较,一旦发现两个对应的字符不同,就根据此序列来决定两个串的大小。
?
”Foxpro”>“Foxmail”
18、关于=和==的比较:
==:
字符串精确比较。
(即两字符串必须长度相等、对应字符相同)
例:
?
”abcde”==“abcd”——.F.
=:
比较字符串时,结果受SETEXACT命令的影响。
Setexactoff时,如果‘=’右边的字符串比左边的短,则左边的字符串取同右边长度相同的子字符串参加比较,反之右边的字符串比左边的长则返回.F.
Setexactoff?
”abcde”=“abcd”——.T.,?
’bc’=’bc‘——.F.
Setexacton时,首先通过在字符串后面加空格的方法使左右字符串的长度相等,然后进行比较。
Setexacton?
“abcde”=“abcd”?
“王一平”=“王”?
“060101”=“06”
其结果都为逻辑值.F.,?
‘bc’=‘bc’——.T.
19、逻辑运算符运算顺序从高到低:
()、 not(!
)\、and、or。
若有关系运算符等其他运算符和逻辑运算符的混合运算,
逻辑运算符的优先级最低。
20、NULL值处理
1)、NULL值具有以下特点:
(1)等价与没有任何值;
(2)与0、空字符串(“”)或空格不同;
(3)排序优先于其他数据;
(4)在计算过程中或大多数函数中可以用到NULL值。
(5)NULL值会影响命令、函数、逻辑表达式和参数行为。
VFP支持的NULL值可以出现在任何使用值和表达式的地方。
2)、几个函数的比较
X=
.null.
“”
0
{//}
EMPTY(X)
.F.
.T.
.T.
.T.
ISBLANK(X)
.F.
.T.
.F.
.T.
ISNULL(X)
.T.
.F.
.F.
.F.
3)、空值的输入
在字段中交互方式:
[ctrl]+[0],在表达式或程序设计中:
.NULL.
4)、NULL值不是一种数据类型即:
当给字段或变量赋null值时,该字段或变量的数据类型不变,只是值为NULL。
5)、空值在逻辑表达式中的行为。
逻辑表达式
表达式的结果
X=.T.
X=.F.
X=null
Xand.null.
.null.
.F.
.null.
Xor.null.
.T.
.null.
.null.
Not.null.
.F.
.T.
.null.
21、在VFP中可以用LOCAL、PRIVATE和PUBLIC关键字指定变量的作用域。
在命令窗口中创建的任何变量都是全局变量。
22、在定义数组时,使用DECLEAR和DIMENSION声明的数组属于私有数组,而使用PUBLIC命令声明的数组属于全局数组,使用LOCAL命令声明的数组属于局部数组。
23、在VFP程序中,如果未加定义直接使用,则默认变量为私有变量,在命令窗口中创建的任何变量和数组具有全局属性。
24、如果要将第一个字符为‘C’的所有变量保存到mVar内存变量文件中,可以使用命令:
SavetomVaralllikec*,如果要将第一个字符为‘M’,第三个字符为N的所有变量保存到名为RFILE的内存变量文件中,可以使用命令:
SavetorfilealllikeM?
N*
25、*和&&都能进行程序的注释,但*将整个命令行定义为注释内容且*必须为命令行的第一个字符,而&&用于命令的后面引导一个注释内容。
操作部分
要求:
常量的表示方法、变量的赋值、常用函数的使用与表达式的构造
1、计算年龄:
?
year(date()-year(csrq)
2、计算圆的面积:
store3.3toR(赋值)s=3.14*R*R(计算)?
round(s,3)(保留三位小数)
3、定义一个一元数组xy和二元数组xz:
dimensionxy(4),xz(5,2)
第三章
理论部分
1、数据库是一个容器,是许多相关的数据库表及其关系的集合。
2、数据库设计的过程:
(1)数据需求分析
(2)确定需要的表(3)确定表的字段(4)确定表之间的关系(5)对设计进行优化
3、VFP数据库的组成:
表、本地视图、远程视图、连接、存储过程
4、一个表最多有255个字段。
5、表与数据库之间的相关性是通过双向链接实现的。
双向链接包括前链和后链。
前链:
保存在数据库文件中,包含表文件的路径和表名。
后链:
保存在表文件中,包含数据库名及其路径。
6、把分散在相关表中的数据通过联结条件把它们收集到一起,构成一张“虚表”,这张“虚表”就是视图。
视图分为:
本地视图和远程视图
7、连接是保存在数据库中的一个定义,指定了数据源的名称。
建立远程数据连接的目的是创建远程视图。
8、存储过程是指在数据库数据上执行特定操作并存储在数据库文件中的程序代码。
9、数据字典是指存储在数据库中用于描述所管理的表和对象的数据。
每一个数据库都带有一个数据字典,存储在数据库文件中。
可用displaydatabase命令查看数据库中的信息。
10、数据库是一个包容器,但并不在物理上包容任何附属对象,在数据库中仅存储了指向表文件的路径指针。
11、每创建一个新的数据库都将生成三个文件:
数据库文件(.DBC),关联的数据库备注文件(.DCT),关联的数据库索引文件(.DCX)
12、创建数据库:
createdatabase打开数据库:
OPENDATABASE
设置当前数据库:
SETDATABASETO数据库名
13、检查数据库的有效性
链接被破坏后可以使用VALIDATEDATABASE命令重建链接
如:
OPENDATABASEtestdata
VALIDATEDATABASERECOVER
如果是从磁盘意外地删除了某个库文件,而表文件中仍保留对该数据库的后链,这个表就不能被添加到其他数据库中,这时需要从表中删除后链,使用命令:
FREETABLE表文件名
14、关闭数据库
CLOSEDATEBASES
CLOSEDATABASESALL——关闭所有打开的数据库和其中的表、所有打开的自由表、所有工作区内所有索引和格式文件。
CLOSEALL——关闭所有的数据库、表、索引以及各种设计器。
15、删除数据库
正确的方法是:
利用项目管理器“移去”按钮进行删除。
说明:
此种方法
(1)可以使与该数据库相关的一系列文件.dbc.dcx.dct一起删除;
(2)使该数据库包含的数据库表自动变成自由表。
不正确的删除方法:
(1)从Windows的资源管理器窗口中直接删除.dbc.dct.dcx文件;
(2)或者利用deletefile命令删除。
此种方法只能删除文件本身,但不会删除该数据库所包含的表中的链接信息。
16、表的记录必须用一个公共的结构来存储,这个公共结构就是表的结构。
表的记录和表的结构组成表。
17、表结构主要包括:
字段名、字段的数据类型、字段的宽度、小数位数、、空值(NULL)支持
字段的宽度
(1)字段宽度必须能足够容纳可能的最长的数据信息。
(2)一
些数据类型的宽度是固定的。
货币型、日期型、日期时间型和双精度型为8字节;
逻辑型为1字节;整型、备注型、通用型为4字节。
整数部分的宽度+小数点1位+小数位数宽度
18、VFP系统启动后,系统默认当前工作区号为1。
一个工作区中只能打开一张表
19、工作区是指用以标识一张打开的表的区域(一块内存区域)。
打开一个表时,必须为该表指定一个工作区。
每个工作区都有一个编号(1-32767)和别名(A~J)
20、函数SELECT()用来测试当前工作区的区号
21、如果一个表同时在多个工作区中打开,且均未指定别名,则在第一次打开的工作区中别名与表名相同,其他工作区中用A~J,W11~W32767表示。
22、表的关闭
1)、界面操作
2)、使用命令
USE——关闭当前工作区中的表
USEIN别名|工作区——关闭非当前工作区中的表
COLSEALL/CLOSEDATABASE/CLOSETABLES——关闭所有工作区中表
3)、在退出VFP时,所有的表被关闭
23、表的独占与共享使用
1)、工具——选项
2)、使用SETEXCLUSIVE命令
SETEXCLUSIVEOFF——设置“共享”为默认打开方式
SETEXCLUSIVEON——设置“独占”为默认打开方式
3)、强行用一种方式打开
在用命令打开表时,加子句“SHARED”(共享)或“EXCLUSIVE”(独占)来指定打开方式。
USExsSHARED——共享方式打开xs表
USEjsEXCLUSIVE——独占方式打开js表
24、记录的定位方式:
绝对定位:
指把指针移动到指定的位置。
相对定位:
把指针从当前位置开始,相对于当前记录向前或向后移动若干个记录位置。
条件定位:
指按照一定的条件自动地在整张表和表的某个指定范围中查找符合该条件的记录。
如果找到,则把指针定位到该记录上,否则将定位到整张表或表的指定范围的末尾。
25、记录定位的实现:
GOTON/SKIP[nRecords]
LOCATEFOR条件[范围]/CONTINUE
❑几个范围选项的含义:
•ALL表中全部记录
•Nextn从当前记录开始的n条记录
•Recordn仅对n这条记录
•Rest当前记录及其后的所有记录。
❑For与while的区别
•For是指表中所有满足条件的记录
•While是指当前记录及其连续满足条件的记录,一旦碰到不满足条件的记录,即使下面还有满足条件的记录,则停止定位。
26、数据的复制
复制表结构:
语法:
COPYSTRUCTURETOTablename[FIEDSFieldList]
功能:
用当前选择的表结构创建一个新的表结构。
如:
USEJS,COPYSTRUCTURETOGZFIELDSgh,xm,csrq
复制表文件:
COPYTO文件名[范围][字段列表][FOR条件];
[[TYPE]SDF|XLS|DELIMITED[WITHDelimiter|
WITHBLANK|WITHTAB|WITHCHARACTERDelimiter]]
例:
将学生表复制到EXCEL文件中。
USEXS,COPYTOXS01XLS
27、记录的顺序有:
逻辑顺序(表中记录的存储顺序)和物理顺序(表被打开使用时,记录的处理顺序)
注:
物理顺序和逻辑顺序可以相同也可以不同,但实际应用中往往不同。
28、对有序文件进行排序,可以有两种方法:
1)、把原表记录按某个逻辑顺序重新写到一个新的文件中,新表与原表大小相同,记录数相等。
不同的仅仅是记录的物理顺序。
2)、建立一个逻辑顺序号和物理顺序号的对照表,将对照表保存到一个新文件中。
生成对照表的速度比重写一遍快。
对照表的文件比实际表文件小得多。
实际应用中,常要从多个角度查找表文件。
29、索引是由一系列记录号组成的一个列表。
记录号在列表中的顺序是按照各个记录的索引关键字的值,从小到大或从大到小进行排列的。
30、用多个字段建立索引表达式,应注意:
1)表达式的计算结果影响索引的结果
如:
“xs.ximing+xs.xb”和“xs.xb+xs.ximing”
2)用多个“数值型”字段求和建立的索引表达式,索引将按字段和,而不是字段本身。
3)不同类型字段构成一个表达式时,必须转换数据类型。
常用转换函数:
STR(),DTOC()等
31、索引标识(Tag)即索引关键字的名称,也称索引名。
32、四种索引类型:
(1)主索引
——在数据表中每张表只能创建一个主索引。
——组成主索引的关键字的字段或表达式在表的所有记录中不能有重复值。
 升级会员
升级会员 