二分类Logistic回归的详细SPSS操作资料下载.pdf
《二分类Logistic回归的详细SPSS操作资料下载.pdf》由会员分享,可在线阅读,更多相关《二分类Logistic回归的详细SPSS操作资料下载.pdf(8页珍藏版)》请在冰点文库上搜索。
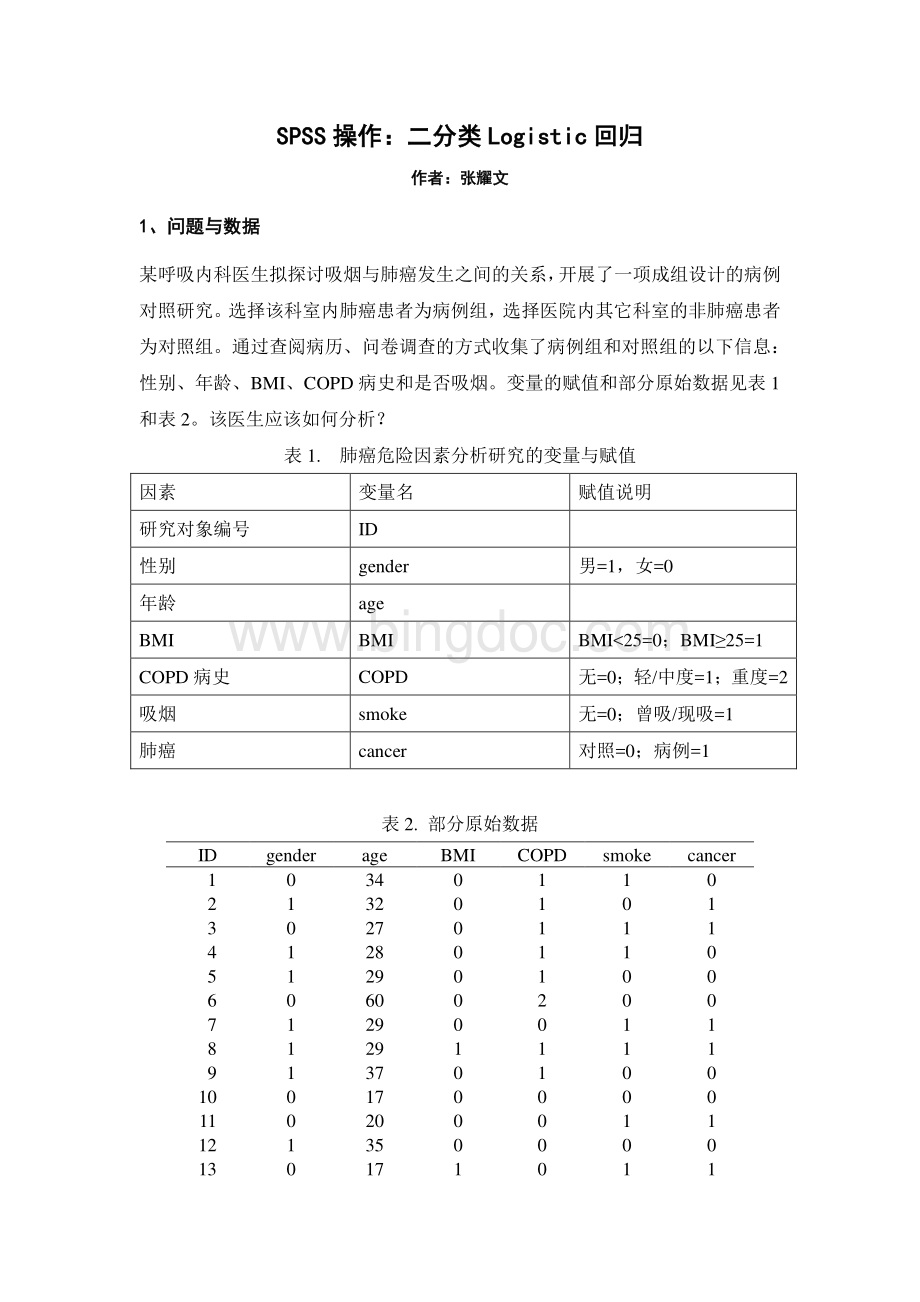
变量的赋值和部分原始数据见表1和表2。
该医生应该如何分析?
表1.肺癌危险因素分析研究的变量与赋值因素变量名赋值说明研究对象编号ID性别gender男=1,女=0年龄ageBMIBMIBMI25=0;
BMI25=1COPD病史COPD无=0;
轻/中度=1;
重度=2吸烟smoke无=0;
曾吸/现吸=1肺癌cancer对照=0;
病例=1表2.部分原始数据IDgenderageBMICOPDsmokecancer10340110213201013027011141280110512901006060020071290011812911119137010010017000011020001112135000013017101122、对数据结构的分析、对数据结构的分析该设计中,因变量为二分类,自变量(病例对照研究中称为暴露因素)有二分类变量(性别、BMI和是否吸烟)、连续变量(年龄)和有序多分类变量(COPD病史)。
要探讨二分类因变量与自变量之间的关系,应采用二分类二分类Logistic回归回归模型模型进行分析。
在进行在进行二分类二分类Logistic回归回归(包括其它(包括其它Logistic回归回归)分析分析前前,如果样本不如果样本不多而变量较多,多而变量较多,建议先通过单变量分析(建议先通过单变量分析(t检验检验、卡方检验等卡方检验等)考察所有自变量)考察所有自变量与因变量之间的关系,与因变量之间的关系,筛掉一些可能无意义的变量,筛掉一些可能无意义的变量,再再进行多因素分析,这样进行多因素分析,这样可以保证结果更加可靠。
即使样本足够大,也不建议直接把所有的变量放入方可以保证结果更加可靠。
即使样本足够大,也不建议直接把所有的变量放入方程直接分析,一定要先弄清楚各个变量之间的相互关系,程直接分析,一定要先弄清楚各个变量之间的相互关系,确定确定自变量进入方程自变量进入方程的形式,这样才能有效的进行分析。
的形式,这样才能有效的进行分析。
本例中单变量分析的结果见表3(常作为研究报告或论文中的表1)。
表3.病例组和对照组暴露因素的单因素比较病例组(病例组(n=85)对照组对照组(n=259)2/t统计量统计量P性别,男(%)56(65.9)126(48.6)7.6290.01年龄(岁),xs40.314.038.612.41.0810.28BMI,n(%)正常48(56.5)137(52.9)0.3290.57超重或肥胖37(43.5)122(47.1)COPD病史,n(%)无21(24.7)114(44.0)14.1230.01轻中度24(28.2)75(29.0)重度40(47.1)70(27.0)是否吸烟,n(%)否18(21.2)106(40.9)10.8290.01是67(78.8)153(59.1)单因素分析中,病例组和对照组之间的差异有统计学意义的自变量包括:
性别、COPD病史和是否吸烟。
此时,应当考虑应该将哪些此时,应当考虑应该将哪些自变量自变量纳入纳入Logistic回归回归模型。
一般情况下,建模型。
一般情况下,建议议纳入的变量有:
纳入的变量有:
1)单因素分析单因素分析差异差异有统计学有统计学意义的变量意义的变量(此时,此时,最好将最好将P值值放宽一些,比如放宽一些,比如0.1或或0.15等等,避免漏掉一些重要因素避免漏掉一些重要因素);
2)单因素分析时,单因素分析时,没有发现差异有统计学意义,但是没有发现差异有统计学意义,但是临床临床上上认为认为与因变量关系密切的自变量与因变量关系密切的自变量。
本研究中,年龄和BMI与因变量没有统计学关联。
但是,临床认为年龄也是肺癌发生的可能危险因素,因此Logistic回归模型中,纳入以下自变量:
性别、年龄、COPD病史和是否吸烟。
此外此外,对于连续变量,如果仅仅是为了调整该变量带来的混杂(不关心该变,对于连续变量,如果仅仅是为了调整该变量带来的混杂(不关心该变量的量的OR值),则可以直接将值),则可以直接将改改变量纳入变量纳入Logistic回归回归模型;
如果关心该变量对模型;
如果关心该变量对因变量的影响程度(关心该变量的因变量的影响程度(关心该变量的OR值),一般不直接将该连续变量纳值),一般不直接将该连续变量纳入模型入模型,而是将连续变量转化为而是将连续变量转化为有序多分类有序多分类变量后纳入模型。
变量后纳入模型。
这是因为,在Logistic回归中直接纳入连续变量,那么对于该变量的OR值的意义为:
该变量每升高一个单位,发生结局事件的风险变化(比如年龄每增加1岁,患肺癌的风险增加1.02倍)。
这种解释在临床上大多数是没有意义的。
33、SPSSSPSS分析方法分析方法
(1)数据录入SPSS
(2)选择AnalyzeRegressionBinaryLogistic(3)选项设置1)主对话框设置:
将因变量cancer送入Dependent框中,将纳入模型的自变量sex,age,BMI和COPD变量Covariates中。
本研究中,纳入age变量仅仅是为了调整该变量带来的混杂(不关心该变量的OR值),因此将age直接将改变量纳入Logistic回归模型。
对于自变量筛选的方法(Method对话框),SPSS提供了7种选择,使用各种方法的结果略有不同,读者可相互印证。
各种方法之间的差别在于变量筛选方法不同,其中Forward:
LR法(基于最大似然估计的向前逐步回归法)的结果相对可靠,但最终模型的选择还需要获得专业理论的支持。
2)Categorical设置:
该选项可将多分类变量(包括有序多分类和无序多分类)变换成哑变量,指定某一分类为参照。
本研究中,COPD是多分类变量,我们指定“无COPD病史”的研究对象为参照组,分别比较“轻/中度”和“重度”组相对于参照组患肺癌的风险变化。
点击Categorical将左侧Covariates中的COPD变量送入右侧CategoricalCovariates中。
点击Contrast右侧下拉菜单,选择Indicator(该下拉菜单内的选项是几种与参照比较的方式,Indicator方式最常用,其比较方法为:
方式最常用,其比较方法为:
第一类或第一类或最后一类为参照类最后一类为参照类,每一类与参照类比较,每一类与参照类比较)。
在ReferenceCategory的右侧选择First(表示选择变量COPD中,赋值最小的,即“0”作为参照。
如果选择Last则表示以赋值最大的作为参照)点击Change点击Continue。
3)Options设置中,勾选如下选项及其意义:
Hosmer-Lemeshowgoodness-of-fit:
检验模型的拟合优度;
CIforexp(B):
结果给出OR值的95%可信区间;
DisplayAtlaststep:
仅展示变量筛选的最后一步结果。
Continue回到主界面OK44、结果解读、结果解读Logistic回归的结果给出了很多表格,我们仅需要重点关注三个表格。
(1)OmnibusTestsofModelCoefficients:
模型系数的综合检验。
其中Model一行输出了Logistic回归模型中所有参数是否均为0的似然比检验结果。
P0.05),认为当前数据中的信息已经被充分提取,模型拟合优度较高。
(3)VariablesintheEquation:
1)由于本次统计过程中筛选变量的方式是Forward:
LR法,因此VariablesintheEquation表格中列出了最终筛选进入模型的变量和其参数。
其中Sig.一列表示相应变量在模型中的P值,Exp(B)和95%CIforEXP(B)表示相应变量的OR值和其95%可信区间。
对于sex,smoke这两个二分类变量,OR值的含义为:
相对于赋值较低的研究对象(sex赋值为“0”的为女性;
smoke赋值为“0”的为不吸烟),赋值较高的研究对象(男性、吸烟者)发生肺癌的风险为是多少(2.308倍、3.446倍)。
2)对于多分类变量COPD,设置中以“0”组作为参照,则得到的结果是“1”组、“2”组分别对应于“0”组的OR值。
在在Logistic回归中回归中,设置过哑变量的设置过哑变量的多分类变量是同进同出的多分类变量是同进同出的,即只要有即只要有一组相对于参照组的一组相对于参照组的OR值值有统计学意义,有统计学意义,则该变量则该变量的的全部分组均全部分组均纳入模型。
纳入模型。
COPD变量的第一行没有OR值,其P值代表该变量总体检验的差异有统计学意义(即至少有一组相对于参照组的OR值有统计学意义)。
3)本研究中的COPD变量以“0”组作为参照,因此COPD
(1)行的参数中给出了“1”相对于“0”组的OR值和P值,而在COPD
(2)行的参数中给出了“2”组相对于“0”组的OR值和P值。
4)Constant为回归方程的截距,在模型中一般没有实际意义,大家可不必关注。
55、撰写结论、撰写结论本研究发现,85例肺癌患者中,吸烟者67例(78.8%);
259例非肺癌患者中,吸烟者153例(59.1%),肺癌患者和非肺癌患者中的吸烟率的差异有统计学意义(2=10.829,P0.01)。
Logistic回归模型在调整了性别和COPD病史后,吸烟者相对于不吸烟者,发生肺癌的风险增加(OR=3.45,95%CI:
1.86-6.40)。
多变量分析的结果见表4(常作为研究报告或论文中的表2)。
表4.肺癌危险因素的Logistic回归分析OR(95%CI)P值性别女1.00男2.31(1.34-3.97)0.01COPD病史无1.00轻/中度1.58(0.81-3.10)重度3.60(1.90-6.82)0.01吸烟无1.00有3.45(1.86-6.40)0.01更多统计学教程,可关注“医咖会”微信公众号。
 升级会员
升级会员 