蒙特卡罗算法与matlab精品教程文档格式.docx
《蒙特卡罗算法与matlab精品教程文档格式.docx》由会员分享,可在线阅读,更多相关《蒙特卡罗算法与matlab精品教程文档格式.docx(47页珍藏版)》请在冰点文库上搜索。
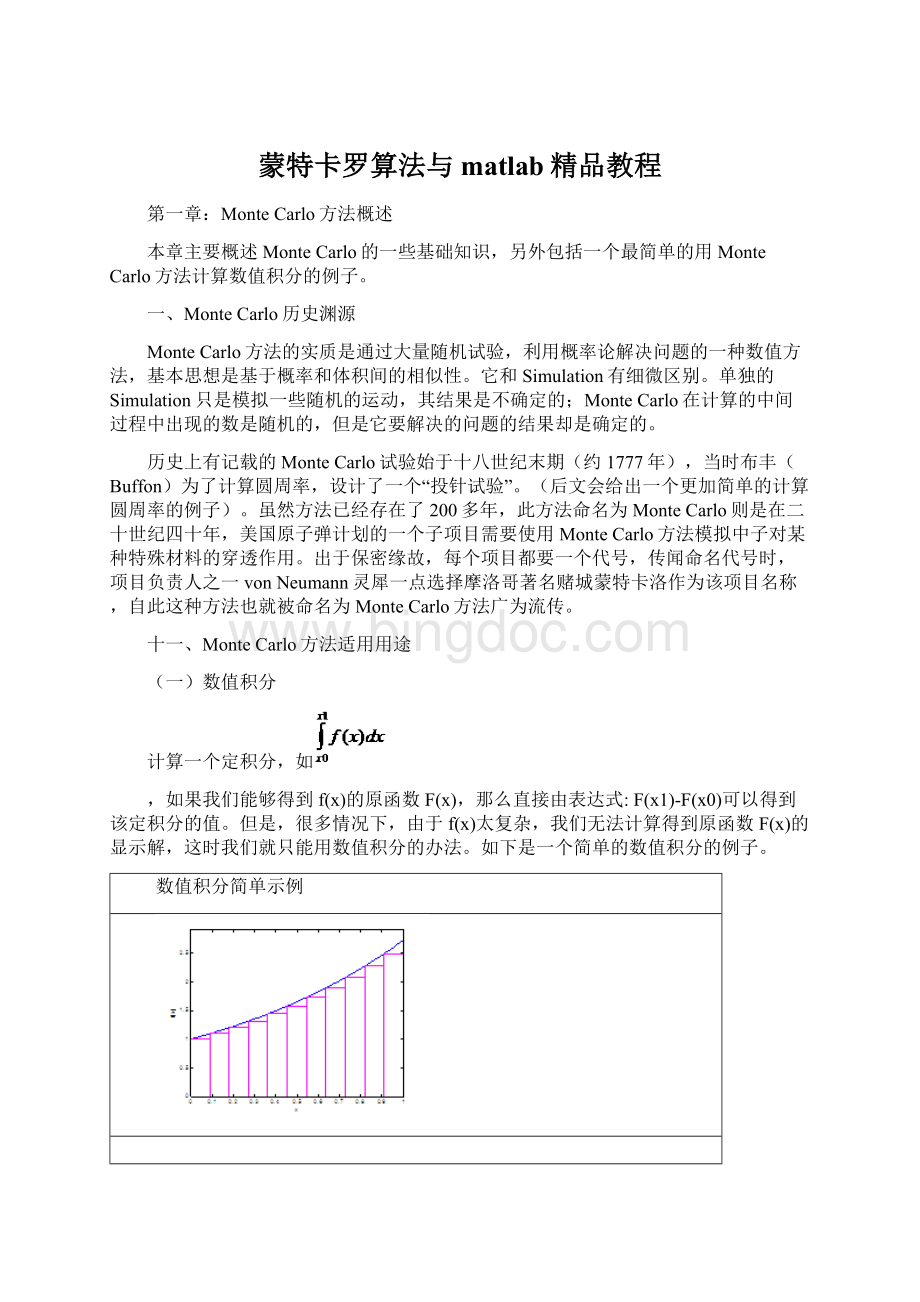
这个例子实质也是随机数值积分,它等价于求此函数的无穷阶范数(
-Norm)在定义域上的积分。
由于在金融产品定价中,这部分内容用的相对较不常见,所以此课程就不介绍随机最优化方法了。
十二、MonteCarlo形式与一般步骤
(一)积分形式
做MonteCarlo时,求解积分的一般形式是:
X为自变量,它应该是随机的,定义域为(x0,x1),f(x)为被积函数,ψ(x)是x的概率密度。
在计算欧式期权例子中,x为期权到期日股票价格,由于我们计算期权价格的时候该期权还没有到期,所以此时x是不确定的(是一随机变量),我们按照相应的理论,假设x的概率密度为ψ(x)、最高可能股价为x1(可以是正无穷)、最低可能股价为x0(可以是0),另外,期权收益是到期日股票价格x和期权行权价格的函数,我们用f(x)来表示期权收益。
(二)一般步骤
我将MonteCarlo分为三加一个步骤:
1.依据概率分布ψ(x)不断生成随机数x,并计算f(x)
由于随机数性质,每次生成的x的值都是不确定的,为区分起见,我们可以给生成的x赋予下标。
如xi表示生成的第i个x。
生成了多少个x,就可以计算出多少个f(x)的值
2.将这些f(x)的值累加,并求平均值
例如我们共生成了N个x,这个步骤用数学式子表达就是
3.到达停止条件后退出
常用的停止条件有两种,一种是设定最多生成N个x,数量达到后即退出,另一种是检测计算结果与真实结果之间的误差,当这一误差小到某个范围之内时退出。
有趣的类比:
积分表达式中的积分符合类比为上式中累加符号,dx类比为1/N(数学知识告诉我们积分实质是极限意义下的累加;
f(x)还是它自己,积分中的ψ(x)可类比为依据ψ(x)生成随机数
4.误差分析
MonteCarlo方法得到的结果是随机变量,因此,在给出点估计后,还需要给出此估计值的波动程度及区间估计。
严格的误差分析首先要从证明收敛性出发,再计算理论方差,最后用样本方差来替代理论方差。
在本课程中我们假定此方法收敛,同时得到的结果服从正态分布,因此可以直接用样本方差作区间估计。
详细过程在例子中解释。
这个步骤的理论意义很重要,但在实际应用中,它的重要性有所淡化,倘若你的老板不太懂这些知识,你报告计算结果时可以只告诉他点估计即可。
注意,前两大步骤还可以继续细分,例如某些教科书上的五大步骤就是将此处的前两步细分成四步。
十三、最简单的例子
举个例子:
计算从
函数从0到2的定积分值
。
数学方法:
我们已知
的原函数是
,那么定积分值就是:
=6.38905609893065。
计算这个数值可以在Matlab中输入代码:
exp
(2)-exp(0)
上面得到的值是此不定积分的真实值。
常规数值积分:
在
区间内取N个点,计算各个点上的函数值,然后用函数值乘以每个区间宽度,最后相加。
Matlab代码:
N=100;
x=linspace(0,2,N);
sum(exp(x).*2/N)
试着调大N的值,你会发现,最后的结果将更接近真实值。
MonteCarlo数值积分法:
内随机取N个点,计算各个点上的函数值,最后求这些函数值的平均值再乘以2(为何要乘以2在后面小节详细讲)。
看Matlab代码:
x=unifrnd(0,2,N,1);
mean(2*exp(x))
同样的,通过增大N,这种方法得到的结果也将越来越接近真实值。
解释
这个例子要求的积分形式是:
,还不完全是
形式,我们先做变换,
,这里
是f(x);
1/2是ψ(x),它表示,在取值范围(0,2)区间内,x服从均匀分布。
前一例子共三条语句,逐句解释如下:
设定停止条件,共做N次MonteCarlo模拟。
按照(0,2)区间均匀分布概率密度对x随机抽样,共抽取N个xi。
此句相当于第一个步骤中的前半部分。
2*exp(x)作用是对每个xi计算f(xi)的值,共可得到N个值,这个相当于第一个步骤后半部分;
Mean()函数的作用是将所有的f(xi)加起来取平均值,相当于第二个步骤。
这段代码中的停止条件隐含于N值设定中,它一次性生成N个x值,完成此次计算后整个程序就结束了。
十四、MonteCarlo方法的优点
对比前面常规数值积分和MonteCarlo数值积分代码,同样数量的N值——也就意味这几乎相同的计算量——常规数值积分结果的精确度要高于MonteCarlo数值积分的结果。
那么,我们为何还需要用MonteCarlo来算数值积分呢?
答案的关键在于,常规数值积分的精度直接取决于每个维度上取点数量,维度增加了,但是每个维度上要取的点却不能减少。
在多重积分中,随着被积函数维度增加,需要计算的函数值数量以指数速度递增。
例如在一重积分
中,只要沿着x轴取N个点;
要达到相同大小的精确度,在s重积分
中,仍然需要在每个维度上取N个点,s个纬度的坐标相组合,共需要计算Ns个坐标对应的f()函数值。
取点越多,会占用计算机大量内存,也需要更长运算时间,最终导致这种计算方法不可行!
MonteCarlo方法却不同,不管是积分有多少重,取N个点计算的结果精确度都差不多。
因此,即使在一重积分的情形下,MonteCarlo方法的效率比不过常规数值积分,但随着积分维度增加,常规数值积分的速度呈指数下降,MonteCarlo方法的效率却基本不变。
经验表明,当积分重数达到4重积分甚至更高时,MonteCarlo方法将远远优于常规数值积分方法。
现在回到金融产品定价,欧式期权理论定价公式只需要一重积分,此时MonteCarlo方法的效果不明显,但是如果我们考虑一个亚式期权:
期限为1年期,期权价格基于此1年内每天某个时点时的价格,全年共252个交易日,这样此亚式期权理论定价公式是一个252重积分。
常规的数值积分方法,需要取N252个点,这个数有多大,你自己去计算一下就知道了(注意:
N取值要远远大于2),常规数值积分方法不可行,只能用MonteCarlo。
综上,如果计算高维度多重积分,如路径依赖的exoticoptions(奇异期权)等金融产品定价,我们一般用的方法都是MonteCarlo。
十五、MonteCarlo方法原理(选读)
MonteCarlo方法计算的结果收敛的理论依据来自于大数定律,且结果渐进地(Asymptotically)服从正态分布的理论依据是中心极限定理。
以上两个属性都是渐进性质,要进行很多次抽样,此属性才会比较好地显示出来,如果MonteCarlo计算结果的某些高阶距存在,即使抽样数量不太多,这些渐进属性也可以很快地达到。
这些原理在理论上意义重大,但由于我们一般遇上的MonteCarlo问题都是收敛的、结果也都是渐进正态分布,所以工作中使用时可以不加考虑。
详细推导见相关书籍。
第二章:
随机数的生成
讲课人:
XaeroChang|课程主页:
http:
//macro2.org/notes/intro2mc
本章第一节会简要复习随机变量的一些概念,但学习本章最好要有一定的数学基础。
第二节主要介绍如何生成一维概率分布的随机数,第三节介绍如何生成高维分布的随机数。
最后略提及伪随机数问题的应对策略。
由前文可知,MonteCarlo积分解决的问题形如
,f(x)值只需由x值决定,因此此处最重要的就是如何生成服从ψ(x)概率分布的随机数。
可以说,正确生成随机数,MonteCarlo方法就做完了一半。
一、随机变量基本概念
(一)随机变量
现实世界中有很多可以用数字来衡量的事物,站在当前时间点来看,它们在未来时刻的值是不确定的。
例如,我们掷一骰子,在它停稳前,我们不可能知道掷出多少点(传说中的赌王除外,哈哈);
例如某只股票在明天的股价,没有人能准确知晓第二天股票的价格(不然他就发惨了!
)。
但是,我们却可以描述这些事物未来各种值的可能性。
(二)离散型随机变量
离散型随机变量最重要的是分布律,即每个取值的概率是多少。
例如掷骰子,我们认为扔出任何一个点的概率都是1/6。
那么掷骰子得到的点数的分布律如下表:
骰子点数
1
2
3
4
5
6
概率
1/6
(三)连续性随机变量
连续型随机变量有两个重要的概念。
概率密度函数(PDF)和累积概率分布函数(CDF),具体定义见数学书籍。
PDF函数本身不是概率,只有对x的某段区间中的PDF积分得到的数值才有概率的含义。
CDF是概率的意思,点x上CDF的值表示该随机变量可能取值小于x的概率的大小。
如图是正态分布的PDF和CDF
(四)多元分布
在这个课程里面,我不将多维的随机变量拆分成多个一维的随机变量来表述,而是将各个维度组合成一个随机变量向量。
多元随机变量分布需要掌握联合分布、边缘分布和条件分布。
联合分布和单变量PDF类似,如果将其对随机变量某个取值范围做积分就可以得到随机变量最终取值落在该区间内的概率。
边缘分布是只考虑多维随机变量中的某一维,其他维度不考虑情况下的PDF
条件分布是固定随机变量在其他维度的取值,再考虑剩余那个维度上的PDF。
如图是一个二维正态分布(两个维度间相关系数为0.3)的示意图。
两个小图分别是第一和第二维度的边缘分布PDF图(都是标准正态分布PDF)。
右上角的大图是依据此二维正态联合分布生成的随机数。
从随机数的疏密程度可以看出联合分布PDF函数在该区域的大小。
研究这些分布不是我们的目的,只是达到目的的手段。
我们所需要做的事情是生成符合各种分布的随机数。
由分布的不同类型——连续型和离散型,常规型(Matlab中有内置函数)和特殊型(Matlab中无内置函数),一维分布和多维分布——我们接下来就各种情况分别讲述如何在Matlab中生成各种各样的随机数。
十六、一维随机数
两个注意事项:
1.生成随机数有两种选择,可以每次只生成一个随机数,直接用此数计算f(x),然后循环重复此过程,最后求平均值;
另一种方法是每次生成全部循环所需的随机数,利用Matlab矩阵运算语法计算f(x),不需要写循环,直接即可求平均值。
前一种方法代码简单,但速度慢;
后一种方法代码相对更难写。
此处一定要掌握如何生成随机数组成的向量和矩阵(单个随机数就是一个1*1的矩阵),在后面章节的例子里面一般会有两个版本的代码分别讲述这两种生成方法。
2.生成了一维的随机数后,可以用hist()函数查看这些数服从的大致分布情况。
(一)Matlab内部函数
a.基本随机数
Matlab中有两个最基本生成随机数的函数。
1.rand()
生成(0,1)区间上均匀分布的随机变量。
基本语法:
rand([M,N,P...])
生成排列成M*N*P...多维向量的随机数。
如果只写M,则生成M*M矩阵;
如果参数为[M,N]可以省略掉方括号。
一些例子:
rand(5,1)%生成5个随机数排列的列向量,一般用这种格式
rand(5)%生成5行5列的随机数矩阵
rand([5,4])%生成一个5行4列的随机数矩阵
生成的随机数大致的分布。
x=rand(100000,1);
hist(x,30);
由此可以看到生成的随机数很符合均匀分布。
(视频教程会略提及hist()函数的作用)
2.randn()
生成服从标准正态分布(均值为0,方差为1)的随机数。
基本语法和rand()类似。
randn([M,N,P...])
randn(5,1)%生成5个随机数排列的列向量,一般用这种格式
randn(5)%生成5行5列的随机数矩阵
randn([5,4])%生成一个5行4列的随机数矩阵
x=randn(100000,1);
hist(x,50);
由图可以看到生成的随机数很符合标准正态分布。
b.连续型分布随机数
如果你安装了统计工具箱(StatisticToolbox),除了这两种基本分布外,还可以用Matlab内部函数生成符合下面这些分布的随机数。
3.unifrnd()
和rand()类似,这个函数生成某个区间内均匀分布的随机数。
基本语法
unifrnd(a,b,[M,N,P,...])
生成的随机数区间在(a,b)内,排列成M*N*P...多维向量。
unifrnd(-2,3,5,1)%生成5个随机数排列的列向量,一般用这种格式
unifrnd(-2,3,5)%生成5行5列的随机数矩阵
unifrnd(-2,3,[5,4])%生成一个5行4列的随机数矩阵
%注:
上述语句生成的随机数都在(-2,3)区间内.
x=unifrnd(-2,3,100000,1);
由图可以看到生成的随机数很符合区间(-2,3)上面的均匀分布。
4.normrnd()
和randn()类似,此函数生成指定均值、标准差的正态分布的随机数。
normrnd(mu,sigma,[M,N,P,...])
生成的随机数服从均值为mu,标准差为sigma(注意标准差是正数)正态分布,这些随机数排列成M*N*P...多维向量。
normrnd(2,3,5,1)%生成5个随机数排列的列向量,一般用这种格式
normrnd(2,3,5)%生成5行5列的随机数矩阵
normrnd(2,3,[5,4])%生成一个5行4列的随机数矩阵
上述语句生成的随机数所服从的正态分布都是均值为2,标准差为3.
x=normrnd(2,3,100000,1);
如图,上半部分是由上一行语句生成的均值为2,标准差为3的10万个随机数的大致分布,下半部分是用小节“randn()”中最后那段语句生成10万个标准正态分布随机数的大致分布。
注意到上半个图像的对称轴向正方向偏移(准确说移动到x=2处),这是由于均值为2的结果。
而且,由于标准差是3,比标准正态分布的标准差
(1)要高,所以上半部分图形更胖(注意x轴刻度的不同)。
5.chi2rnd()
此函数生成服从卡方(Chi-square)分布的随机数。
卡方分布只有一个参数:
自由度v。
chi2rnd(v,[M,N,P,...])
生成的随机数服从自由度为v的卡方分布,这些随机数排列成M*N*P...多维向量。
chi2rnd(5,5,1)%生成5个随机数排列的列向量,一般用这种格式
chi2rnd(5,5)%生成5行5列的随机数矩阵
chi2rnd(5,[5,4])%生成一个5行4列的随机数矩阵
上述语句生成的随机数所服从的卡方分布的自由度都是5
x=chi2rnd(5,100000,1);
6.frnd()
此函数生成服从F分布的随机数。
F分布有2个参数:
v1,v2。
frnd(v1,v2,[M,N,P,...])
生成的随机数服从参数为(v1,v2)的卡方分布,这些随机数排列成M*N*P...多维向量。
frnd(3,5,5,1)%生成5个随机数排列的列向量,一般用这种格式
frnd(3,5,5)%生成5行5列的随机数矩阵
frnd(3,5,[5,4])%生成一个5行4列的随机数矩阵
上述语句生成的随机数所服从的参数为(v1=3,v2=5)的F分布
x=frnd(3,5,100000,1);
从结果可以看出来,F分布集中在x正半轴的左侧,但是它在极端值处也很可能有一些取值。
7.trnd()
此函数生成服从t(Student'
stDistribution,这里Student不是学生的意思,而是Cosset.W.S.的笔名)分布的随机数。
t分布有1个参数:
trnd(v,[M,N,P,...])
生成的随机数服从参数为v的t分布,这些随机数排列成M*N*P...多维向量。
trnd(7,5,1)%生成5个随机数排列的列向量,一般用这种格式
trnd(7,5)%生成5行5列的随机数矩阵
trnd(7,[5,4])%生成一个5行4列的随机数矩阵
上述语句生成的随机数所服从的参数为(v=7)的t分布
x=trnd(7,100000,1);
可以发现t分布比标准正太分布要“瘦”,不过随着自由度v的增大,t分布会逐渐变胖,当自由度为正无穷时,它就变成标准正态分布了。
接下来的分布相对没有这么常用,同时这些函数的语法和前面函数语法相同,所以写得就简略一些——在视频中也不会讲述,你只需按照前面那几个分布的语法套用即可,应该不会有任何困难——时间足够的话这是一个不错的练习机会。
8.betarnd()
此函数生成服从Beta分布的随机数。
Beta分布有两个参数分别是A和B。
下图是A=2,B=5的beta分布的PDF图形。
生成beta分布随机数的语法是:
betarnd(A,B,[M,N,P,...])
9.exprnd()
此函数生成服从指数分布的随机数。
指数分布只有一个参数:
mu,下图是mu=3时指数分布的PDF图形
生成指数分布随机数的语法是:
betarnd(mu,[M,N,P,...])
10.gamrnd()
生成服从Gamma分布的随机数。
Gamma分布有两个参数:
A和B。
下图是A=2,B=5Gamma分布的PDF图形
生成Gamma分布随机数的语法是:
gamrnd(A,B,[M,N,P,...])
11.lognrnd()
生成服从对数正态分布的随机数。
其有两个参数:
mu和sigma,服从这个这样的随机数取对数后就服从均值为mu,标准差为sigma的正态分布。
下图是mu=-1,sigma=1/1.2的对数正态分布的PDF图形。
生成对数正态分布随机数的语法是:
lognrnd(mu,sigma,[M,N,P,...])
12.raylrnd()
生成服从瑞利(Rayleigh)分布的随机数。
其分布有1个参数:
B。
下图是B=2的瑞利分布的PDF图形。
生成瑞利分布随机数的语法是:
raylrnd(B,[M,N,P,...])
13.wblrnd()
生成服从威布尔(Weibull)分布的随机数。
其分布有2个参数:
scale参数A和shape参数B。
下图是A=3,B=2的Weibull分布的PDF图形。
生成Weibull分布随机数的语法是:
wblrnd(A,B,[M,N,P,...])
还有非中心卡方分布(ncx2rnd),非中心F分布(ncfrnd),非中心t分布(nctrnd),括号中是生成服从这些分布的函数,具体用法用:
help函数名
查找。
c.离散型分布随机数
离散分布的随机数可能的取值是离散的,一般是整数。
14.unidrnd()
此函数生成服从离散均匀分布的随机数。
Unifrnd是在某个区间内均匀选取实数(可为小数或整数),Unidrnd是均匀选取整数随机数。
离散均匀分布随机数有1个参数:
n,表示从{1,2,3,...N}这n个整数中以相同的概率抽样。
unidrnd(n,[M,N,P,...])
这些随机数排列成M*N*P...多维向量。
unidrnd(5,5,1)%生成5个随机数排列的列向量,一般用这种格式
unidrnd(5,5)%生成5行5列的随机数矩阵
unidrnd(5,[5,4])%生成一个5行4列的随机数矩阵
上述语句生成的随机数所服从的参数为(10,0.3)的二项分布
生成的随机数大致的分布
 升级会员
升级会员 