编译原理课程设计词法分析.docx
《编译原理课程设计词法分析.docx》由会员分享,可在线阅读,更多相关《编译原理课程设计词法分析.docx(18页珍藏版)》请在冰点文库上搜索。
编译原理课程设计词法分析
一、实验题目
设计、编制、调试一个识别一简单语言单词的词法分析程序。
程序能够识别基本字、标识符、无符号整数、浮点数、运算符和界符)。
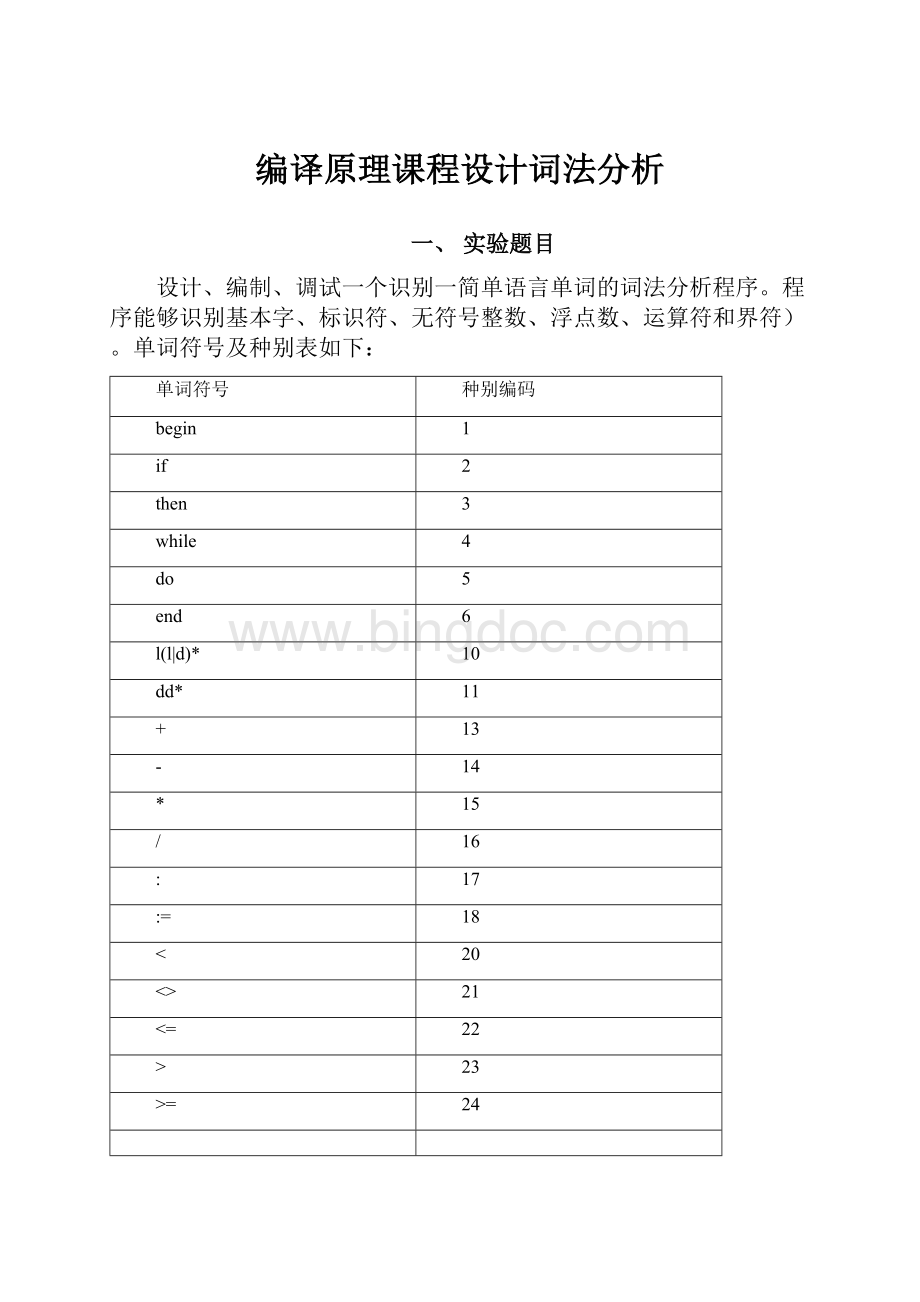
单词符号及种别表如下:
单词符号
种别编码
begin
1
if
2
then
3
while
4
do
5
end
6
l(l|d)*
10
dd*
11
+
13
-
14
*
15
/
16
:
17
:
=
18
<
20
<>
21
<=
22
>
23
>=
24
=
25
;
26
(
27
)
28
#
0
二、实验目的
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
三、实验要求
词法分析程序需具备词法分析的功能:
输入:
所给文法的源程序字符串。
(字符串以“#”号结束)
输出:
二元组(syn,token或sum)构成的序列。
其中:
syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数。
例如:
对源程序beginx:
=9:
ifx>9thenx:
=2*x+1/3;end#的源文件,经过词法分析后输出如下序列:
(1,begin)(10,x)(18,:
=)(11,9)(26,;)(2,if)……
四、实验步骤
基本设计思路
Ø基本字作为一类特殊的标识符来处理:
识别出标识符,差基本字表,给出相应种别码。
基本字表置初值:
char*rwtab[6]={"begin","if","then","while","do","end"};(字符指针的数组)
Ø识别无符号整数是将数字串转换为无符号整数。
我们在getchar()的时候是把数字当做字符从外部输出读取的。
将数字串345#转换为整数:
(3*10+4)*10+5=345送到sum中
Ø程序主要由2个函数组成,主函数main()和扫描子函数scanner()。
扫描程序每次读取1个独立意义的单词符号,并判断单词类型。
主程序做相应处理后做控制台输出。
流程框图
图1主程序
图2扫描子程序
算法设计
词法分析程序所用的较为重要的全局变量和需调用的函数如下:
1)ch字符变量,存放当前读进的源程序字符。
2)token[8]字符数组,存放构成单词符号的字符串。
3)prog[80]字符数组,存放所有用户输入的字符。
4)syn整数,存放当前单词的种别码。
5)sum双精度浮点型变量,存放无符号整数,或者浮点数。
6)isDecimal整数,是否为浮点数。
isDecimal为1,则为浮点数。
7)decimal双精度浮点型变量(double),浮点数的小数部分。
8)isExp整数,是否为指数形式表示的浮点数(即是否存在符号E或者e)。
isExp为1,则为指数形式。
9)index整数,指数形式的幂。
10)isNegative整数,是否为负数幂。
isNegative为1,则为负数幂,如123E-2。
11)scanner()扫描子程序。
12)getchar()从控制台读取一个字符数据。
13)doublepow(doublex,doubley),计算x的y次幂。
14)intstrcmp(char*str1,char#str2),字符串比较。
函数相关说明
1.接收用户输入:
getchar()和do…while循环的组合
do{
ch=getchar();
prog[p++]=ch;
}while(ch!
='#');//输入以#号键结束
2.输出到控制台:
do…while循环中,扫描出单词后(扫描程序还会判断种别码syn)输出。
do{
scanner();//扫描,单词
switch(syn)
{
case11:
if(isDecimal==0)
{
printf("(%2d,%8d)\n",syn,(int)sum);
break;
}
elseif(isExp==1)
{
printf("(%2d,%10.5e)\n",syn,sum);
isExp=0;
isDecimal=0;
break;
}
elseif(isDecimal==1)
{
printf("(%2d,%8.4f)\n",syn,sum);
isDecimal=0;
break;
}
case-1:
printf("inputerror\n");
break;
default:
printf("(%2d,%8s)\n",syn,token);
}
}while(syn!
=0);
3.浮点数的识别,先识别数字,再识别.,再识别数字,再识别E或e,再识别-,再识别数字。
elseif((ch>='0')&&(ch<='9'))
{
while((ch>='0')&&(ch<='9'))
{
sum=sum*10+ch-'0';//ch中数字本身是当做字符存放的
ch=prog[p++];
}
if(ch=='.')
{
isDecimal=1;
ch=prog[p++];
while((ch>='0')&&(ch<='9'))
{
//pow(x,y)计算x的y次幂
temp=(ch-'0')*pow(0.1,++count);
decimal=decimal+temp;
//AddToDec();
ch=prog[p++];
}
sum=sum+decimal;
}
if(ch=='e'||ch=='E')
{
isExp=1;
ch=prog[p++];
if(ch=='-')
{
isNegative=1;
ch=prog[p++];
}
while((ch>='0')&&(ch<='9'))
{
//指数
index=index*10+ch-'0';
ch=prog[p++];
}
if(isNegative)
sum=sum*pow(0.1,index);
else
sum=sum*pow(10,index);
}
p--;
syn=11;
}
输入与输出
词法分析程序需具备词法分析的功能:
输入:
所给文法的源程序字符串。
(字符串以“#”号结束)
输出:
二元组(syn,token或sum)构成的序列。
其中:
syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数。
程序运行结果
五、实验方案设计实现
用C语言实现。
六、实验程序亮点描述
浮点数处理部分:
巧妙利用doublepow(doublex,doubley)函数,简化了浮点数处理部分。
如果是简单浮点数,如1.23,出现“.”符号,置isDeminal为1,用%f输出。
如果稍微复杂一点,指数形式,但是正数幂,如1.23E2,出现“E”符号,置isExp为1,用%e输出。
如果更复杂一点,指数形式,但是负数幂,如1.23E-2,出现“-”号,置isNegative为1,仍然用%e输出。
如果是有符号数(有符号整数或者有符号浮点数),在识别出“+”或者“-”之后,再读后边一个字符,如果是数字,那么转至识别数字的代码段,并在末尾将sum进行相应处理。
如果后边字符不是数字,证明“+”或者“-”是加减号,而非正负号。
七、实验程序使用说明
用户输入待识别字符串(并以“#”结尾,表示字符串输入结束),回车后程序自动输出词法分析结果。
八、实验心得体会
词法分析的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
通过本试验的完成,更加加深了对词法分析原理的理解。
最初是按照老师课堂上的C语言实现这个思路进行的,但是后来老师要求将识别数字拓展到浮点数(即实数)。
由于本人C语言功底不够扎实,最后只得再回过头去看了一下C语言的语法,不过最后还是通过自己的力量把东西给做出来了。
很有成就感!
参考文献
[1]张素琴,吕映芝等.编译原理[M].第2版.北京:
清华大学出版社,2005.2
[2]王雷,刘志成等.编译原理课程设计[M].北京:
电子工业出版社,2002
[3]何炎祥等.编译程序构造[M].武汉:
武汉大学出版社,1988
[4]HolubA.CompilerDesigninC[M].Prentice-Hall,1990
源程序代码
#include
#include
#include
charprog[80];//存放所有输入字符
chartoken[8];//存放词组
charch;//单个字符
intsyn,p,m,n;//syn:
种别编码
doublesum;
intcount;
intisSignal;//是否带正负号(0不带,1负号,2正号)
intisDecimal;//是否是小数
doubledecimal;//小数
intisExp;//是否是指数
intindex;//指数幂
intisNegative;//是否带负号
doubletemp;
inttemp2;
voidscanner();
char*rwtab[6]={"begin","if","then","while","do","end"};
voidmain()
{
p=0;
count=0;
isDecimal=0;
index=0;
printf("\nPleaseinputstring:
\n");
do{
ch=getchar();
prog[p++]=ch;
}while(ch!
='#');//输入以#号键结束
p=0;
do{
scanner();//扫描,单词
switch(syn)
{
case11:
if(isDecimal==0)
{
//加了1个强制类型转换
printf("(%2d,%8d)\n",syn,(int)sum);
break;
}
elseif(isExp==1)
{
printf("(%2d,%10.5e)\n",syn,sum);
isExp=0;
isDecimal=0;
break;
}
elseif(isDecimal==1)
{
printf("(%2d,%8.4f)\n",syn,sum);
isDecimal=0;
break;
}
case-1:
printf("inputerror\n");
break;
default:
printf("(%2d,%8s)\n",syn,token);
}
}while(syn!
=0);
}
voidscanner()
{
sum=0;
decimal=0;
m=0;
for(n=0;n<8;n++)
token[n]=NULL;
ch=prog[p++];//从prog中读出一个字符到ch中
while(ch=='')//跳过空字符(无效输入)
ch=prog[p++];
if(((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z')))//ch是字母字符
{
while(((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||((ch>='0')&&(ch<='9')))
{
token[m++]=ch;//ch=>token
ch=prog[p++];//读下一个字符
}
token[m++]='\0';
p--;//回退一格
syn=10;//标识符
//如果是"begin","if","then","while","do","end"标识符中的一个
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
elseif((ch>='0')&&(ch<='9'))
{
IsNum:
if(isSignal==1)
{
//token[m++]='-';
}
while((ch>='0')&&(ch<='9'))
{
sum=sum*10+ch-'0';//ch中数字本身是当做字符存放的
ch=prog[p++];
}
if(ch=='.')
{
isDecimal=1;
ch=prog[p++];
while((ch>='0')&&(ch<='9'))
{
//pow(x,y)计算x的y次幂
temp=(ch-'0')*pow(0.1,++count);
decimal=decimal+temp;
//AddToDec();
ch=prog[p++];
}
sum=sum+decimal;
}
if(ch=='e'||ch=='E')
{
isExp=1;
ch=prog[p++];
if(ch=='-')
{
isNegative=1;
ch=prog[p++];
}
while((ch>='0')&&(ch<='9'))
{
//指数
index=index*10+ch-'0';
ch=prog[p++];
}
//10的幂
//123e3代表123*10(3)
//sum=sum*pow(10,index);是错误的
if(isNegative)
sum=sum*pow(0.1,index);
else
sum=sum*pow(10,index);
}
if(isSignal==1)
{
sum=-sum;
isSignal=0;
}
p--;
syn=11;
}
elseswitch(ch)
{
case'<':
m=0;
token[m++]=ch;
ch=prog[p++];
if(ch=='>')
{
syn=21;//<>对应21
token[m++]=ch;
}
elseif(ch=='=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case'>':
m=0;
token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case':
':
m=0;
token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
p--;
}
break;
case'+':
temp2=prog[p];
if((temp2>='0')&&(temp2<='9'))
{
isSignal=2;
ch=prog[p++];
gotoIsNum;
}
syn=13;
token[m++]=ch;
break;
case'-':
temp2=prog[p];
if((temp2>='0')&&(temp2<='9'))
{
isSignal=1;
ch=prog[p++];
gotoIsNum;//转到数字的识别
}
syn=14;
token[m++]=ch;
break;
case'*':
syn=15;
token[m++]=ch;
break;
case'/':
syn=16;
token[m++]=ch;
break;
case'=':
syn=25;
token[m++]=ch;
break;
case';':
syn=26;
token[m++]=ch;
break;
case'(':
syn=27;
token[m++]=ch;
break;
case')':
syn=28;
token[m++]=ch;
break;
case'#':
syn=0;
token[m++]=ch;
break;
default:
syn=-1;
}
}
 升级会员
升级会员 