SPSS操作方法聚类分析报告文档格式.docx
《SPSS操作方法聚类分析报告文档格式.docx》由会员分享,可在线阅读,更多相关《SPSS操作方法聚类分析报告文档格式.docx(20页珍藏版)》请在冰点文库上搜索。
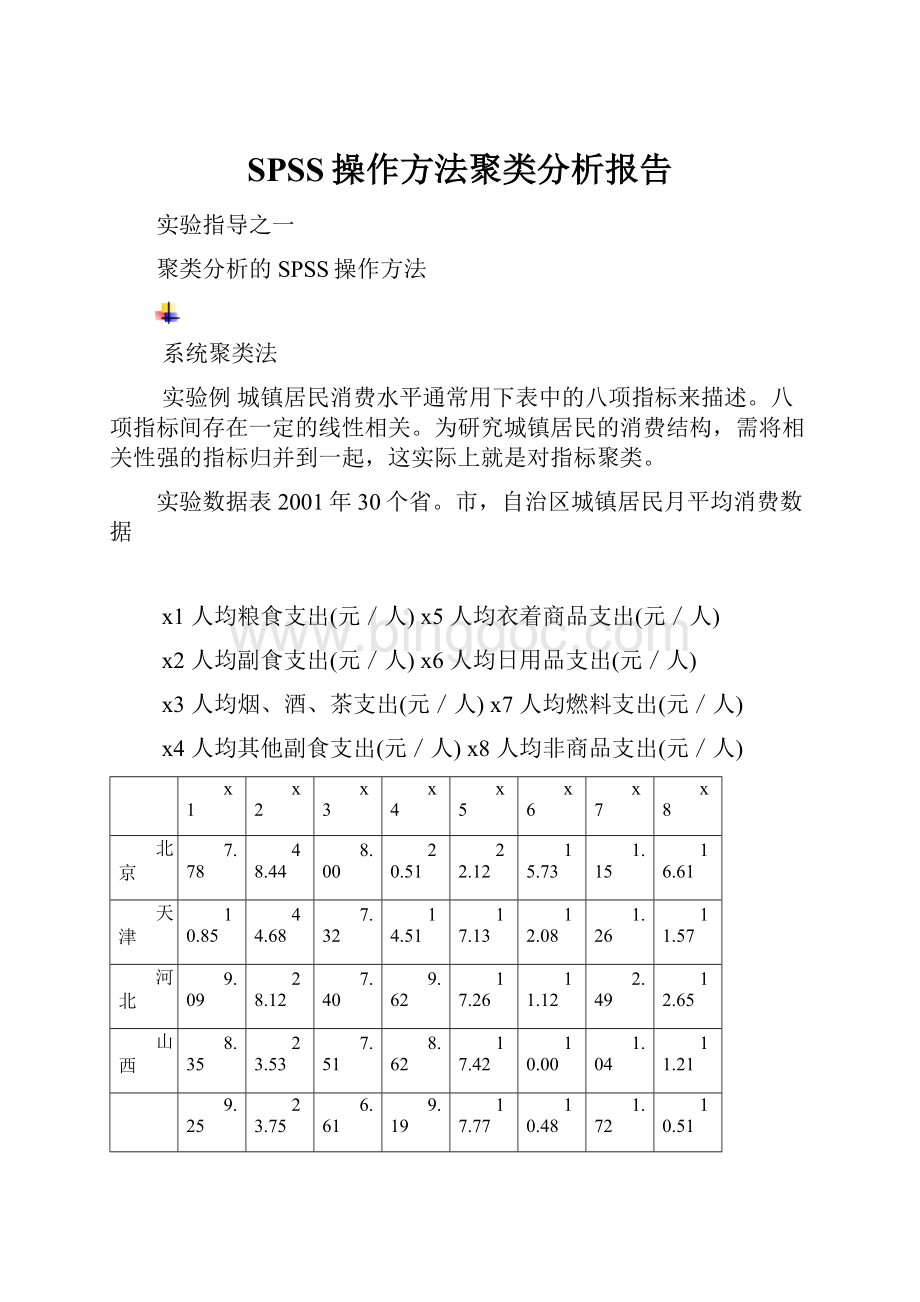
辽宁
7.90
39.77
8.49
12.94
19.27
11.05
2.04
13.29
吉林
8.19
30.50
4.72
9.78
16.28
7.60
2.52
10.32
7.73
29.20
5.42
9.43
19.29
上海
8.28
64.34
22.22
20.06
15.52
0.72
22.89
江
7.21
45.79
7.66
10.36
16.56
12.86
2.25
11.69
浙江
7.68
50.37
11.35
13.30
19.25
14.59
2.75
14.87
安徽
8.14
37.75
9.61
13.15
9.76
1.28
11.28
福建
10.60
52.41
7.70
9.98
12.53
11.70
2.31
14.69
江西
6.25
35.02
6.28
10.03
7.15
1.93
10.39
山东
8.82
33.70
7.59
10.98
18.82
14.73
1.78
10.10
河南
9.42
27.93
8.20
8.14
16.17
1.55
湖北
8.67
36.05
7.31
7.75
16.67
11.68
2.38
12.88
湖南
6.77
38.69
6.01
14.79
11.44
1.74
13.23
广东
12.47
76.39
5.52
11.24
14.52
22.00
5.46
25.50
广西
7.27
52.65
3.84
9.16
13.03
15.26
1.98
14.57
海南
13.45
55.85
5.50
7.45
9.55
9.52
2.21
16.30
四川
7.18
40.91
8.94
17.60
12.75
1.14
14.80
贵州
7.67
35.71
8.04
8.31
15.13
7.76
1.41
13.25
云南
37.69
7.01
16.15
11.08
0.83
11.67
西藏
7.94
39.65
20.97
20.82
22.52
12.41
1.75
7.90
陕西
9.41
28.20
5.77
10.80
16.36
11.56
1.53
12.17
甘肃
27.98
9.01
9.32
15.99
9.10
1.82
青海
10.06
28.64
10.52
10.05
16.18
8.39
1.96
10.81
宁夏
8.70
10.53
19.45
1.66
11.96
新疆
6.93
29.85
4.54
9.49
16.62
10.65
1.88
13.61
系统聚类法的SPSS操作:
1.从数据编辑窗口点击Analyze→Classify→HierachicalCluster,(见图1)
图1系统聚类法
打开层次聚类法对话如图2。
图2系统聚类法对话框
选择需要进行聚类分析的变量进入Variable框后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法:
Cases对样品聚类(Q型;
系统默认),
Variable对指标变量聚类(R型),本例选择。
在Display栏中选择默认的输出项。
2.点击Statistics按钮,打开对话框如图3.
图3Statistics对话框
✧Agglomerationschedule输出凝聚状态表(聚类进度表);
本例选择。
✧Ploximitymatrix输出个体间的距离矩阵,本例选择。
✧ClusterMembership栏中显示每个观测量被分派到的类。
None不输出。
Simplesolution指定分类数,并输出样本所属类,单一解。
Rengeofsolution指定输出从m到n类的各样本所属类。
多个解。
选好后返回主对话框。
3.单击Method按钮,打开对话框如图4-1.
✧ClusterMethod:
选择聚类方法:
SPSS中提供7种聚类方法,分别是:
类间平均,类平均,最短距离,最长距离,重心法,中值法,最小平方和法。
本例选择类间平均。
✧Measure栏:
对距离的测度方法选择
SPSS中提供了三种类型:
Interval等间距度量的变量(连续型),Counts计数型变量(离散型)和Binary二值变量。
Interval等间隔测度的变量方法包括:
Euclideandistance欧氏距离;
SquaredEuclideandistance欧氏平方距离;
Cosine夹角余弦(R型聚类);
PearsonCorrelation皮尔逊相关系数距离(R型聚类),本例选择此项。
Chebychev契比雪夫距离;
block距离;
Minkowski明氏距离;
Customized用户自定义距离--即变量绝对值的第p次幂之和的第r次根。
p与r由用户指定。
图4-1Method对话框
✧TransformValues栏,选择消除数量级差的方法(见图4-2),依次是:
None不作处理(系统默认);
本例选择此项。
Zscores标准化处理;
Range-1to1各变量值除全距;
Range0to1各变量值减最小值后除全距;
Maximummagnitudeof1各变量值除最大值;
Meanof1各变量值除以均值;
Standarddeviationof1各变量值除以标准差。
图4-2Method对话框
4.单击Plots按钮,打开对话框如图5.
图5Plots对话框
✧Dendrogram表示输出树形图,本例选择此项。
✧Icicle表示输出冰柱图。
其中,
Allclusters表示输出聚类分析每个阶段的冰柱图;
Specifiedrangeofcluster表示只输出某个阶段的冰柱图,输入从第几步开始到第几步结束,中间间隔几步。
✧Orientationk栏中指定如何显示冰挂图:
Vertical纵向显示,本例选择此项。
Horizontal横向显示。
图6SaveNewVariables对话框
5.单击Save按钮,打开SaveNewVariables对话框,如图6所示。
选择是否将聚类的结果以变量形式保存在数据文件中。
变量名为:
clun_m,其中n表示类数,m表示第m次分析。
✧ClusterMembership栏
None不输出
Simplesolution指定分类数,并输出样本所属类。
单一变量。
多个变量。
当选择结束后,在主对话框中点击OK,可得下面的输出表和图。
ProximityMatrix两两变量间距离矩阵(相关系数矩阵)
Case
MatrixFileInput
人均粮食支出(元/人)
人均副食支出(元/人)
人均烟、酒、茶支出(元/人)
人均其他副食支出(元/人)
人均衣着商品支出(元/人)
人均日用品支出(元/人)
人均燃料支出(元/人)
人均非商品支出(元/人)
.000
.334
-.055
-.061
-.289
.197
.349
.319
-.023
.399
-.156
.716
.414
.835
.533
.497
.033
-.139
-.258
.698
.478
-.171
.313
.284
-.208
-.081
.408
.710
AverageLinkage(BetweenGroups)类间平均
AgglomerationSchedule凝聚状态进度表;
Stage
ClusterCombined
Coefficients
StageClusterFirstAppears
NextStage
Cluster1
Cluster2
1
2
8
6
.713
5
3
4
.515
7
.407
.299
.004
凝聚状态进度表:
第一列(Stage)表示聚类的进度顺序;
第二、三列(Clustercombine)表示每一步将哪两类合并;
第四列(Cofficients)表示被合并的两类之间的距离;
第五、六列(StageClusterFirstAppares)表示被合并的两类上一次合并分别是在哪一步形成的。
0表示被合并的类为单个样品。
最后一列(NextStage)表示每一步形成的新类将在哪一步参与下一次合并。
VerticalIcicle冰柱图
Numberofclusters
X
Dendrogram表示输出树形图(谱分析图)
******HIERARCHICALCLUSTERANALYSIS******
DendrogramusingAverageLinkage(BetweenGroups类间平均)
RescaledDistanceClusterCombine
CASE0510152025
LabelNum+---------+---------+---------+---------+---------+
X22
X88
X66
X77
X11
X44
X55
X33
二:
K-聚类法的具体操作
以例10.4为例,说明快速聚类法的操作过程。
1.在数据窗口单击Analyze→Classify→K-MeanCluster打开对话框(见图7)
图7K-MeansClusterAnalysis对话框
将变量选入Variables栏;
将标识变量选入LabelCases栏(可省略)
将分类数输入Numberof框(系统默认为2),本例中选择4.
✧Method栏聚类方法栏
Iterateandclassify(按K-means算法)叠代分类(系统默认)。
Classifyonly仅按初始类别中心点分类(不叠代)。
✧Centers类中心数据的输入与输出(可省略)
Readinitialfrom使用指定数据文件中的数据作为初始类中心(文件格式参考Writefinalas文件格式)
选择Writefinalas把聚类结果中的各类中心数据保存到指定的文件。
本例中选择系统默认项。
2.单击Iterate按钮,打开Iterate对话框如图8所示:
✧MaximumIterations限定K-Means算法的迭代次数,系统默认值10
✧ConvergenceCriterion-指定限定收敛标准,系统默认值为0。
✧Userunningmeans限定在每个观测量被分配到一类后即刻计算新的类中心,不选此项表示只有当全部样本的类分配完后再计算类中心,可以节省运算时间,所以一般情况下不选择此项。
本例中选择默认项。
图8Iterate对话框
3.单出Save按钮,打开Save对话框见图9.
ClusterMember在原数据文件中保存分类结果(本例选择)。
Distancefromclustercenter在原数据文件中保存各观测量距所属类中心间的欧氏距离。
图9Save对话框
4.单击Options按钮,打开Options对话框见图10。
✧Statistics栏
Initialclustercenters输出初始类中心。
ANOVAtable输出方差分析表
Clusterinformationforeachcase每个观测量的分类信息(分类结果和该观测量距所属类中心的距离等)
图10Options对话框
✧MissingValues栏
Excludecaseslistwise将出现在Variables变量表中变量带有缺失值得观测量从分析中剔除(系统默认)
Excludecasespairwise只有当一个观测量的全部聚类变量值均缺失时才将其从分析中剔除,否则根据所有其他非缺失变量值把它分配到最近的一类中去。
全部选择完成后得到输出结果。
InitialClusterCenters初始类中心
Cluster
x1人均粮食支出(元/人)
21.30
23.68
25.56
19.07
x2人均副食支出(元/人)
124.89
173.30
171.65
73.18
x3人均烟、酒、饮料支出(元/人)
35.43
17.43
22.30
18.01
x4人均其他副食支出(元/人)
73.98
43.59
40.53
29.38
x5人均衣着支出(元/人)
93.01
53.66
57.13
64.51
x6人均日用杂品支出(元/人)
20.58
16.86
12.60
8.91
x7人均水电燃料支出(元/人)
43.97
65.02
54.03
38.14
x8人均其他非商品支出(元/人)
433.73
385.94
225.08
155.45
IterationHistorya迭代过程表
Iteration
ChangeinClusterCenters
29.250
38.950
25.321
8.415
2.404
a.Convergenceachievedduetonoorsmallchangeinclustercenters.Themaximumabsolutecoordinatechangeforanycenteris.000.Thecurrentiterationis3.Theminimumdistancebetweeninitialcentersis88.803.
ClusterMembership(聚类结果)
CaseNumber
地区
Distance
北京
天津
57.295
河北
13.014
山西
30.528
34.511
辽宁
37.350
吉林
20.520
21.396
9
上海
29.128
10
14.371
11
浙江
30.023
12
安徽
35.519
13
福建
45.005
14
江西
32.834
15
山东
33.839
16
河南
25.206
17
湖北
13.689
18
湖南
36.637
19
广东
20
广西
45.453
21
海南
67.004
22
重庆
19.289
23
四川
24.567
24
贵州
27.326
25
云南
26.228
26
西藏
61.066
27
陕西
28.348
28
甘肃
20.175
29
青海
17.874
30
宁夏
22.448
31
新疆
18.804
聚类结果中的第四列显示的是各样本与其所属类的中心之间的距离。
上述结果可通过“save”按钮设置,保存至原始数据文件中。
FinalClusterCenters类中心
x1人均粮食支出(元/人)
20.80
22.29
19.72
x2人均副食支出(元/人)
145.27
131.38
91.46
x3人均烟、酒、饮料支出(元/人)
39.86
31.64
20.63
x4人均其他副食支出(元/人)
64.95
44.19
33.93
x5人均衣着支出(元/人)
89.70
65.48
59.43
x6人均日用杂品支出(元/人)
16.32
13.06
9.96
x7人均水电燃料支出(元/人)
49.44
42.48
38.91
x8人均其他非商品支出(元/人)
417.01
234.53
171.13
ANOVA方差分析表
Error
F
Sig.
MeanSquare
df
14.170
5.710
2.482
.082
5809.646
474.087
12.254
459.585
76.568
6.002
.003
913.557
34.833
26.226
842.129
145.065
5.805
54.180
3.931
 升级会员
升级会员 