weka算法参数整理资料下载.pdf
《weka算法参数整理资料下载.pdf》由会员分享,可在线阅读,更多相关《weka算法参数整理资料下载.pdf(31页珍藏版)》请在冰点文库上搜索。
Leverage(杠杆率)P(A,B)-P(A)P(B);
Leverage=0时A和B独立,数值越大A和B的关联性越强。
Conviction(确信度)P(A)P(!
B)/P(A,!
B)(!
B表示B没有发生)Conviction也是用来衡量A和B的独立性。
从它和lift的关系(对B取反,代入Lift公式后求倒数)可以看出,这个值越大,A、B越关联。
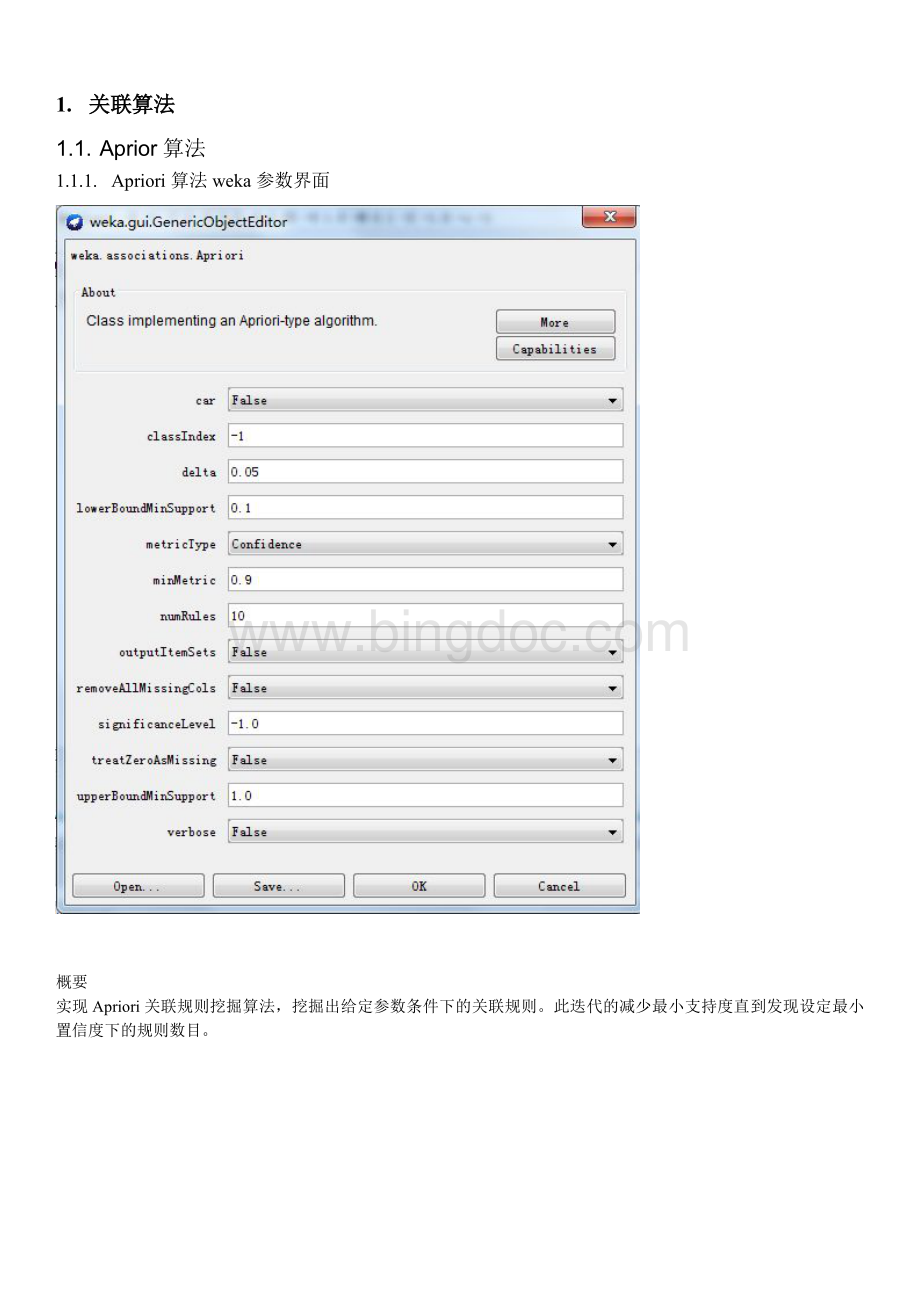
minMetric最小度量值0.9根据metricType取值不同Confidence(0,1);
lift1;
leverage0;
conviction(0,1)numRules规则数目101,+int关联算法产生规则的数目outputItemSets输出项集FalseFalse不输出频繁项集True输出频繁项集removeAllMissingCols移除空列FalseFalse不移除所有值都缺失的列True移除所有值都缺失的列significanceLevel显著性水平-1?
(0,1)2检验的显著性水平,-1则不进行检验。
(仅适用于置信度度量)treatZeroAsMissing按照缺失值处理零FalseFalse不按照缺失值的相同方式处理零(标称型的第一个值)True按照缺失值的相同方式处理零(标称型的第一个值)upperBoundMinSupport最小支持度上限1(lowerBoundMinSupport,1迭代过程中最小支持度的上限;
迭代过程中从该值开始降低。
verbose详细模式FalseFalse算法不以冗余模式运行True算法以冗余模式运行2.聚类聚类2.1.weka聚类主界面及参数说明2.1.1.聚类算法主界面2.1.2.聚类算法主界面参数说明英文名称中文翻译配置说明Usetrainingset使用训练集使用训练集训练并直接使用训练集测试。
Suppliedtestset提供测试集使用训练集训练模型,从文件中加载一组测试实例,单击“Set.”按钮选择测试文件,进行模型测试。
Percentagesplit分割百分比取出特定百分比的数据作为训练数据,其他作为测试数据。
Classtoclustersevaluations类作为评估准则比较所选择的簇与预先指定的类的匹配程度。
Storeclusterforvisualization为可视化保存簇选择后训练完成后,保存簇以供可视化使用2.2.SimpleKMeans算法2.2.1.SimpleKMeans算法参数配置用户界面和开发模式界面2.2.2.SimpleKMeans聚类算法参数配置说明英文名称中文翻译默认值取值范围参数说明canopyMaxNumCanopiesToHoldInMemory内存中最大canopy数目1001,+)如果用canopy聚类方法进行初始化,这个参数就是在内存中保存的最大的候选canopies数目。
canopyMinimumCanopyDensity最低canopy密度2.0?
在使用canopy初始化时,在修剪时的canopy最低密度。
canopyPeriodicPruningRate修剪周期10000?
如果用canopy初始化,参数为修剪低密度canopies周期。
canopyT1Canopy聚类T1半径-1.25(T2,+)canopy聚类时T1半径,当小于0时,T1=(-values)*T2。
canopyT2Canopy聚类T2半径-1(-,T1)canopy聚类时T2半径,当值为负数时,根据属性标准差求出。
debug设置调试模式FalseFalse调试信息不输出True输出调试信息displayStdDevs显示标准差FalseFalse不显示数值属性的标准差,不统计标称属性每类的数目。
True显示数值属性的标准差,或统计标称属性没类的数目。
distanceFunction距离函数EuclideanDistanceEuclideanDistance欧氏距离Manhattandistance马氏距离doNotCheckCapabilities不检查适用范围FalseFalse在聚类之前,检查聚类器的使用范围。
True在聚类之前,不检查聚类器的使用范围。
dontReplaceMissingValues不替换缺失值FalseFalse在全局范围内用平均值或中数替换缺失值True不替换fastDistanceCalc加速距离计算FalseFalse根据cut-off值加速距离计算True不加速距离计算initializationMethod初始化质心方法RandomRandom随机选取质心k-means+先使用k-means+聚类算法初始化质心Canopy先使用Canopy聚类算法初始化质心farthestfirst先使用farthestfirsty聚类算法初始化质心maxIterations最大迭代次数5001,+)迭代过程中达到最大迭代次数结束本次聚类。
numClusters簇数目22,N)设定聚类个数,即最后被聚成几类。
numExecutionSlots最大执行线程数目11,?
设置成可用的cpu数目preserveInstancesOrder保持实例顺序FalseFalse保持实例顺序True不保持实例顺序reduceNumberOfDistanceCalcsViaCanopies减少计算距离数目FalseFalse在用canopy聚类初始化时,减少计算距离的数目。
Trueseed随机数种子10使用的随机数种子,不随机化则该值设为-12.3.EM聚类算法2.3.1.EM聚类算法适用范围Class类Attributes属性NoclassNumericEmptynominalNominalMissingvaluesUnaryBinary2.3.2.EM聚类算法参数界面2.3.3.EM聚类算法参数说明英文名称中文翻译默认值取值范围参数说明debug设置调试模式FalseFalse调试信息不输出True输出调试信息displayModelInOldFormat以旧格式显示结果FalseFalse以新的形式输出结果,当聚类数目比较少时比较合适。
Ture以旧的形式输出结果,当聚类的数目比较多的时候比较合适。
doNotCheckCapabilities不检查适用范围FalseFalse在聚类之前,检查聚类器的使用范围。
maxIterations最大迭代次数1001,+)最大的迭代次数maximumNumberOfClusters最大的聚类数目-1-1,1,N聚类数目不超过这个值;
当为-1时,交叉验证自动选择。
minLogLikelihoodImprovementIteratingminLogLikelihoodImprovementCVminStdDevnumClusters簇数目-1-1,1,N设定结果中簇的数目。
当为-1时,交叉验证自动确定。
设置可用的cpu数目numfolds折数10交叉验证的折数,判定最好的聚类数目,其中一折用于验证,其他用于训练。
seed随机数种子10使用的随机数种子,不随机化则该值设为-13.分类算法分类算法3.1.分类算法主界面英文名称中文翻译配置说明Usetrainingset使用训练集使用训练集训练并直接使用训练集测试。
Cross-validation交叉验证把数据分成k份,从第1份开始,作为测试数据,其他作为训练数据集,一直到第k份结束,验证模型的能力。
Percentagesplit分割百分比取出特定百分比的数据作为训练数据集训练模型,其他数据作为测试数据。
以上所述训练数据集和测试数据集均为模型验证时候的数据集,与模型的建立无关,模型建立均用实验提供的全部训练数据集。
3.2.分类算法输出选项界面英文名称中文翻译配置说明Outputmodel输出模型输出通过完整训练集得到的分类模型,以便能够浏览、可视化等。
Outputper-classstats输出每类的统计信息输出每个分类的TPrate,FPrate,查准率/查全率以及True/False统计信息。
Outputentropyevaluationmeasures?
输出熵评估量度输出中包括熵评估度量Outputconfusionmatrix输出混淆矩阵输出中包括分类器对测试数据集预测得到的混淆矩阵Storepredictionforvisualization为可视化保留预测保存分类器的预测结果,以便可视化。
Errorplotpointsizeproportionaltomargin?
Outputprediction输出预测分别以csv、html、null(不输出)plaintext、xml格式输出对测试数据集的预测,可输出到指定文件。
Cost-sensitiveevaluation成本敏感评估成本矩阵用于评估错误率,点击set按钮允许用户指定所使用的成本矩阵。
Randomseedforxval/%split取样的随机种子随机抽取测试数据时产生随机数的种子Preserveorderforsplit取样时保持顺序抽取测试数据集时是否保持数据的顺序抽取,如果不选择此选项,则随机抽取。
Outputsourcecode输出源代码输出构建模型的java源代码,并能指定java类的名称。
3.3.分类算法评价尺度参数界面及解释CorrectCorrectlyclassifiedinstances正确分类的实例输出正确分类的个数及其比例IncorrectIncorrectlyclassifiedinstances错误分类的实例输出错位分类的个数及其比例KappaKappastatisticKappa统计评价分类器与真实分类之间差异,并考虑到分类器与真实分类偶然一致的情况。
取值范围为-1,1。
K=1表示完全与真实分类相同即全部预测正确,k=0表示与随机分类器相同。
此统计量越接近1表明分类器越优秀。
TotalcostTotalCost总代价代价敏感分析中根据代价矩阵计算的总代价。
代价越大模型预测越差。
AveragecostAverageCost平均代价总代价/验证数据集中实例数目。
KBrelationsK&
BRelativeInfoScoreKBinformationK&
BInformationScorecorrelationCorrelationcoefficient相关系数预测值与实际值之间的相关系数。
(数值性状显示此指标)Complexity0Classcomplexity|order0ComplexityschemeClasscomplexity|schemeComplexityimprovementComplexityimprovement(Sf)MAEMeanabsoluteerror平均绝对误差误差先取绝对值,然后取平均值。
RMSERootmeansquarederror均方根误差误差取平方,然后取平均值,在取根。
RAERelativeabsoluteerror相对绝对误差参照附录公式RRSERootrelativesquarederror相对均方根误差参照附录公式CoverageCoverageofcases(0.95level)案例的覆盖度regionsizeMeanrel.regionsize(0.95level)TPrateTPrate真阳性率TP/P=TP/(TP+FN),实际正类中被预测为正类的比例,数值越高,说明预测正类的准确度高,不容易将正类预测为负类。
FPrateFPrate假阳性率FP/N=FP/(FP+TN),实际负类中被预测为正类的比例。
数值越高,说明分类器越容易将负类预测为正类,分类器效果越差。
precisionprecision查准率TP/(TP+FP),被预测为正类中实际正类的比例,数值越高说明预测的越准确。
FalloutFP/(TP+FP),1-precision(weka?
)recallrecall查全率TP/(TP+FN),被分类器正确预测的正样本比例,数值越高,说明预测正类的准确度高,不容易将正类预测为负类。
查全率等于真阳性率。
F-measuresF-measuresF度量2*TP/(2*TP+FP+FN),查准率和查全率的调和平均数。
值偏向查准率和查全率较低的数值;
较高的F度量确保查准率和查全率都比较高。
LiftLift提升根据每个MCCMCCMatthews相关系数MCC=(TP*TN-FP*FN)/(TP+FP)*(TP+FN)*(TN+FP)*(TN+FN)0.5,同时考虑了FP和FN,并适用于不平衡问题(两个类的比例相差很大)。
取值在-1,1之间,1代表完美的预测,0代表与随机分类器效果一样,-1代表预测结果与实际结果完全不一致。
ROCareaROCarea接受者操作特征曲线下面积0,1越接近1说明分类器效果越好,等于0.5说明分类器和随机分类效果一致。
ROC曲线越靠近左上方,说明分类器的分类效果越好。
PRCareaPRCarea查准率/查全率曲线下面积显示PRC曲线下面积,0,1范围的小数WeightedAvgWeightedAvg加权平均值对各个类的参数加权平均,权重为实际分类中各类占的比例。
3.4.分类算法结果可视化英文名称中文翻译描述Viewinmainwindow在主窗口查看在主窗口中显示输出,与单击该条目的功能相同。
Viewinseparatewindow在单独的窗口查看打开新的独立的窗口显示结果。
Saveresultbuffer保存本次运行结果将结果保存到本地磁盘文件Deleteresultbuffer删除本次运行结果直接从缓存中删除本次运行结果Loadmodel加载模型从二进制文件中加载一个预先训练过的模型Savemodel保存模型将模型对象保存为二进制的文件,对象以java序列化对象的格式保存。
保存后可以直接加载。
Re-evaluatemodeloncurrenttestset用当前测试数据集重新评估模型用当前测试数据集重新评估模型,与Testmodel中选择Suppliedtestset效果相同Re-applythismodelsconfiguration?
VisualizeClassifiererrors可视化分类器错误正确分类的实例用十字表示,错误分类的实例用方块表示。
Visualizetree查看结果树查看分类的树形图形Visualizemargincurve查看边缘曲线Margin定义为预测为实际分类的概率减去预测其他分类中最高概率(分类概率)的差值。
差值越接近1说明预测越准确,越接近-1预测效果越差。
Visualizethresholdcurve查看阈值曲线Cost/benefitanalysis成本/收益分析Visualizecostcurve查看成本曲线3.4.1.VisualizeClassifiererrors可根据需要选择X轴和Y轴坐标多分类实际的类表示颜色,如果分类正确则用十字,否则用方块表示。
3.4.2.Visualizetree决策树决策树是根据所有数据训练的模型,与模型验证无关。
3.5.J48算法参数英文名称中文翻译默认值取值范围参数说明binarySplit构建二叉树FalseFalse每个根节点可以有多个叶子节点True每个根节点有两个叶子节点collapseTree折叠树TureTure无论剪掉哪些分支,都不降低训练误差ConfidenceFactor置信系数用于修剪的置信系数(数值越小,导致更多的修剪)debug调试FalseFalse如果设置为True,输出额外信息到控制台。
doNotCheckCapability不检测适用性FalseFalse在分类器构建之前检测分类器的使用范围Ture在分类器构建之前不检测分类器的使用范围doNotMakeSplitPointActualValueminNumObj最少对象数目每个叶子节点中最小的实例数目numFolds折数确定用于减少错误修剪的数据量。
一折用于修剪,其余用于生成树ReduceErrorPruning减少误差修剪是否使用减小误差修剪代替C4.5修剪。
saveInstanceData保存实例数据是否要为可视化保存训练数据seed随机种子使用减少错误修剪时,用于进行subtreeRaising子树提升是否在修剪时考虑子树提升操作unpruned未修剪FalseFalse对生成的决策树进行剪枝Ture不对生成的决策树进行剪枝useLaplace使用Laplace是否基于Laplace对平滑的叶子进行计数useMDLcorrection使用MDL矫正是否在查找数值属性分类时使用MDL矫正4.附录(详细解释)附录(详细解释)4.1.混淆矩阵4.2.Kappa统计量http:
/en.wikipedia.org/wiki/Cohens_kappawiki解释例子:
分类的混淆矩阵预测的类ABC合计实际的类A200222B115319C021012合计21171553overallprobabilityofrandomagreement:
Pr(e)=(21/53)*(22/53)+(17/53)*(19/53)+(15/53)*(12/53)theobservedpercentageagreementPr(a)=(20+15+3)/53Kappa=(Pr(a)-Pr(e)/(1-Pr(e)4.3.Margincurve4.4.ROC曲线4.5.代价敏感学习4.6.MSE,RMSE,MAE,RSE,RRSE,RAE,correlationcoefficient解释4.7.上升图及上升因子的计算对应上图红点信息对应上图蓝点信息。
Precision和Lift结果类似,表示随着样本的增加预测精度和提升度的变化。
6314Lift=6/(N*SampleSize)/9/N=6/0.5/9=1.33336:
为这个阈值点以上样本中TP数目N:
为样本总数SampleSize:
为这个阈值点样本数目占总数目的比例此例子中为0.59:
为全部样本中的TP
 升级会员
升级会员 