Nokia干扰矩阵建立算法详解Word格式文档下载.doc
《Nokia干扰矩阵建立算法详解Word格式文档下载.doc》由会员分享,可在线阅读,更多相关《Nokia干扰矩阵建立算法详解Word格式文档下载.doc(10页珍藏版)》请在冰点文库上搜索。
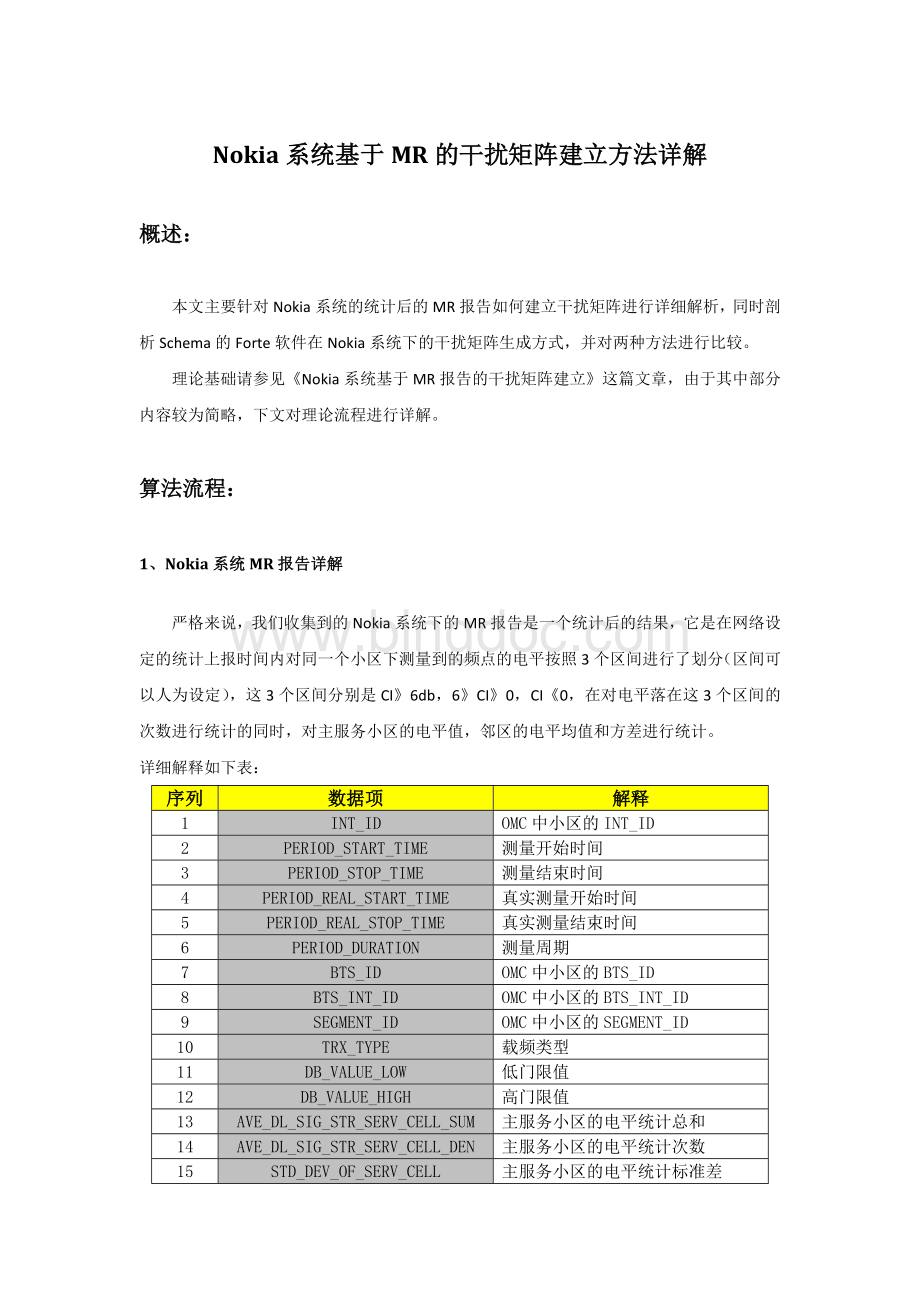
14
AVE_DL_SIG_STR_SERV_CELL_DEN
主服务小区的电平统计次数
15
STD_DEV_OF_SERV_CELL
主服务小区的电平统计标准差
16
AVE_DL_SIG_STR_ADJ_CELL
测量邻区的平均电平
17
NCC
测量邻区的BCC
18
BCC
测量邻区的NCC
19
BCCH
测量邻区的BCCH
20
STD_DEV_OF_ADJ_CELL
测量邻区的电平标准差
21
NBR_OF_SAMPLES_IN_CLASS_1
测量邻区的电平落在1区间的次数
22
NBR_OF_SAMPLES_IN_CLASS_2
测量邻区的电平落在2区间的次数
23
NBR_OF_SAMPLES_IN_CLASS_3
测量邻区的电平落在3区间的次数
24
Expr1023
未知
25
BSC_GID
26
BTS_GID
表1MR格式详解
完整的MR报告由两个文件构成:
DAC(DefinedAdjacentCell)和CF(ChannelFinder),分别对应有邻区关系的测量统计和没有邻区关系的测量统计,需要注意的是CF文件比DAC少了上述表格中13,14,15这3个统计值,因为对于一个小区同一段时间内的统计来说,主服务小区的电平测量值是相同的,所以CF中的这些值和DAC是相同的。
将两个表合并可以得到完整的MR报告。
1.1MR报告的处理
1)获取主服务小区的平均电平
根据表格1中的13,14项,用13的值除以14的值,得到主服务小区的平均电平。
2)获取服务小区所测量的小区
根据17,18,19项,即BCCH+BSIC,结合OMC中的c_adjacent文件定位出测量小区的小区号。
3)获取所测量小区的平均电平
表1中的16项。
4)获取统计时间内的平均CI值
利用2.1计算的结果减去16项的结果,得出当前测量统计时间内的平均CI。
1.2基于FER的干扰矩阵建立
我们采用帧误码率FER(FrameEraseRate)来衡量干扰质量的大小。
CI和FER的转换公式如下:
(1)
因此多个MR报告产生的干扰矩阵的公式也变为:
(2)
下图为FER和Ci的关系曲线:
图1FER和CI关系图
1.3计算步骤:
i.由统计平均CI计算FER;
ii.根据统计次数对FER进行加权处理得出绝对干扰值;
iii.对干扰值进行归一化处理。
算法流程图(针对单小区)
AVE_DL_SIG_STR_SERV_CELL_SUM/AVE_DL_SIG_STR_SERV_CELL_DEN得到服务小区电平
服务小区电平-AVE_DL_SIG_STR_ADJ_CELL得到平均CI
根据计算FER
根据NBR_OF_SAMPLES_IN_CLASS_1+NBR_OF_SAMPLES_IN_CLASS_1+NBR_OF_SAMPLES_IN_CLASS_1计算测量次数
测量次数*FER得到加权FER
对加权FER进行归一化处理得到干扰百分比
2、根据SchemaForte软件获取干扰矩阵的方法
2.1MR数据简介
SchemaForte是一套比较成熟的运用MR进行频率优化的软件,虽然它的算法流程并未开放,但是通过软件建立环境的生成报告可以手动计算网络的干扰矩阵,方法如下:
(1)第一步,运用Forte按照标准流程针对Nokia系统建立环境数据,导入收集到的MR数据;
(2)第二步,运用Forte软件将建立的环境数据和MR报告数据统一的导出成Schema的标准格式SchemaFormat文件,它包括如下文件:
c2i.txt
cellNameHistory.txt
ChannelGroups.txt
freqConstraints.txt
frequencySeparation.txt
HandoverLocking.txt
Handover.txt
HardwareEquipment.txt
hostates.txt
IndoorOutdoor.txt
kpis.txt
network.properties
relationConstraints.txt
RxLevels.txt
RxQual.txt
Sectors.txt
Traffic.txt
理论上来说,这是Forte软件对各个厂家设备进行数据格式的标准化处理,这些文件也说明了Forte软件不管针对哪个厂家设备,在进行环境建立,算法生成时所需要的各种网络信息,至少包括小区信息、干扰信息、切换信息、频点信息、接收电平、接收质量、话务、KPI指标等。
(3)第三步,计算干扰矩阵,由上表的第一个文件c2i.txt就是Forte软件的干扰矩阵原始表,通过它可以计算干扰值。
首先看一下表结构:
ServingSector
InterferingSector
Shadowed
Mean
STD
10002
10215
FALSE
12.28
5.91
10218
48.97
14.9
10454
49.23
16.09
10528
69.57
10702
29.69
12.02
10754
43.57
13.8
10873
21.41
10.8
10913
22.39
10.81
10969
71.83
10983
68.05
19017
16.31
9.04
各个字段分别表示服务小区,干扰小区,未知,平均CI值,平均方差。
2.2理论基础
下面介绍一下如何从CI分布来计算干扰概率
根据GSM基本理论,我们测量到的电平值服从正态分布(不考虑瑞利分布的影响),根据概率学原理,如果
C和I不相关,
那么也服从正态分布,且
(5)
结合GSM对同频CI的保护比,一般设为12db(9db为规范要求,加上3db余量)那么在服从的情况下,就可以计算同频下可能发生干扰的概率,如下如所示:
12db线
直线左边的曲线与X轴所夹的面积即为干扰概率
2.3计算流程
这里按照9db标准计算:
根据(MEAN-9)/STD=a标准化正态分布
计算N(0,1)在a处的值b
1-b得出绝对干扰概率值f
根据服务小区对f进行归一化计算干扰百分比F
2.4Forte功能显示
Forte软件的功能很多,在表示小区的干扰时,不仅在数值上能够显示,在每个频点上也能够显示相应的干扰值,对外部所有小区的干扰值以及外部小区对该小区的干扰总值,同时能够在地图上用不同的颜色显示出来。
如下图所示,在图中颜色越深表示干扰的程度越高(干扰值越大):
根据我的推算,Forte软件在进行干扰分级时,各个级别划分规则如下:
同频干扰概率绝对值
干扰等级显示
0.5<
=f<
50-100
0.3<
0.5
30-50
0.2<
0.3
20-30
0.1<
0.2
10-20
0.05<
0.1
5-10
0.03<
0.05
3-5
0.01<
0.03
1-3
0.005<
0.01
0.5-1
0.001<
0.005
0.1-0.5
0.<
0.001
0-0.1
下面是一个实验证明,这和上图中的显示颜色是一致的:
BTS_NAME
adj_cell
Schema_MEAN
Schema_STD
计算的同频干扰概率绝对值
干扰等级
颜色
10722
10876
9.86
6.43
0.6293
深红
30722
11.65
8.17
0.516
39018
12.93
9.95
0.4641
红色
30876
31.11
10.18
0.0307
黄色
30098
14.2
9.12
0.4052
20876
31.38
10.24
0.0294
浅黄色
10098
15.68
10.08
0.3596
30793
18.12
9.14
0.2546
浅红
10161
18.86
10.12
0.2514
29842
20.13
11.49
0.242
19731
20.03
9.91
0.209
29018
10.21
0.1562
橙色
20722
25.23
11.1
0.117
19862
24.47
11.68
0.1446
19842
39.95
0.0823
浅橙色
30007
43.84
0.0559
19018
46.41
0.0427
39842
42.86
16.95
0.0344
19642
46.49
17.27
0.0233
20732
46.2
19071
51.07
0.0256
20014
39.35
13.48
0.0217
10793
43.75
15.48
0.0202
19622
49.84
18.46
0.0207
10927
47.61
16.74
0.017
30732
54.91
0.0162
29862
48.88
14.96
0.0069
浅绿色
30377
36.09
10.61
0.0116
10803
56.71
0.0129
10732
55.66
19.53
10252
57.72
0.0113
10387
44.63
13.84
0.0094
10014
59.45
0.0089
39731
59.54
16.64
0.0022
绿色
20213
66.92
0.0031
30311
66.45
0.0033
19632
66.87
29071
67.15
0.003
30161
68.44
0.0024
20907
67.99
0.0026
30803
68.84
0.0023
39862
71.88
0.0014
30247
72.78
0.0019
3、算法实例
下面是一份MR报告小区10722的统计数据:
其中没有参与计算的数据已经略去:
根据1.3流程计算结果和Schema计算结果如下:
Schema计算结果
FER计算结果
两者绝对误差
14.63%
14.57%
-0.06%
12.00%
17.33%
5.33%
10.79%
10.85%
0.06%
0.71%
0.59%
-0.12%
9.42%
10.70%
1.28%
0.68%
0.41%
-0.27%
8.36%
7.22%
-1.14%
5.92%
4.49%
-1.43%
5.85%
5.36%
-0.49%
5.63%
5.65%
0.02%
4.86%
3.60%
-1.26%
3.63%
3.46%
-0.17%
2.72%
5.80%
3.08%
3.36%
3.40%
0.04%
1.91%
0.80%
-1.11%
1.30%
0.79%
-0.51%
0.99%
0.39%
-0.60%
1.07%
0.27%
0.54%
0.46%
-0.08%
0.70%
0.14%
-0.56%
0.60%
0.63%
0.51%
0.24%
0.47%
0.09%
-0.38%
0.48%
0.50%
0.40%
0.21%
-0.19%
0.38%
0.11%
0.16%
0.23%
0.07%
0.10%
0.30%
0.05%
-0.25%
-0.24%
0.26%
0.08%
-0.18%
0.22%
0.17%
-0.05%
-0.13%
-0.01%
-0.02%
0.03%
-0.04%
0.01%
0.00%
-0.03%
总结
从计算结果来看,FER和Schema计算结果偏差是不大的,主要的误差出现在干扰概率很小的小区,这在绝对误差上看不出,但在相对误差上还是有差距的,要想获得更完美的算法还需要进一步优化。
 升级会员
升级会员 