目标检测RCNN到SSD学习工作总结文档格式.docx
《目标检测RCNN到SSD学习工作总结文档格式.docx》由会员分享,可在线阅读,更多相关《目标检测RCNN到SSD学习工作总结文档格式.docx(16页珍藏版)》请在冰点文库上搜索。
但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。
我们继续合并区域,直到所有区域都结合在一起。
下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的ROI。
(作者为了保证能够划分的完全,对于相似度,作者提出了可以多样化的思路,不但使用多样的颜色空间(RGB,Lab,HSV等等),还有很多不同的相似度计算方法。
论文考虑了颜色、纹理、尺寸和空间交叠这4个参数)
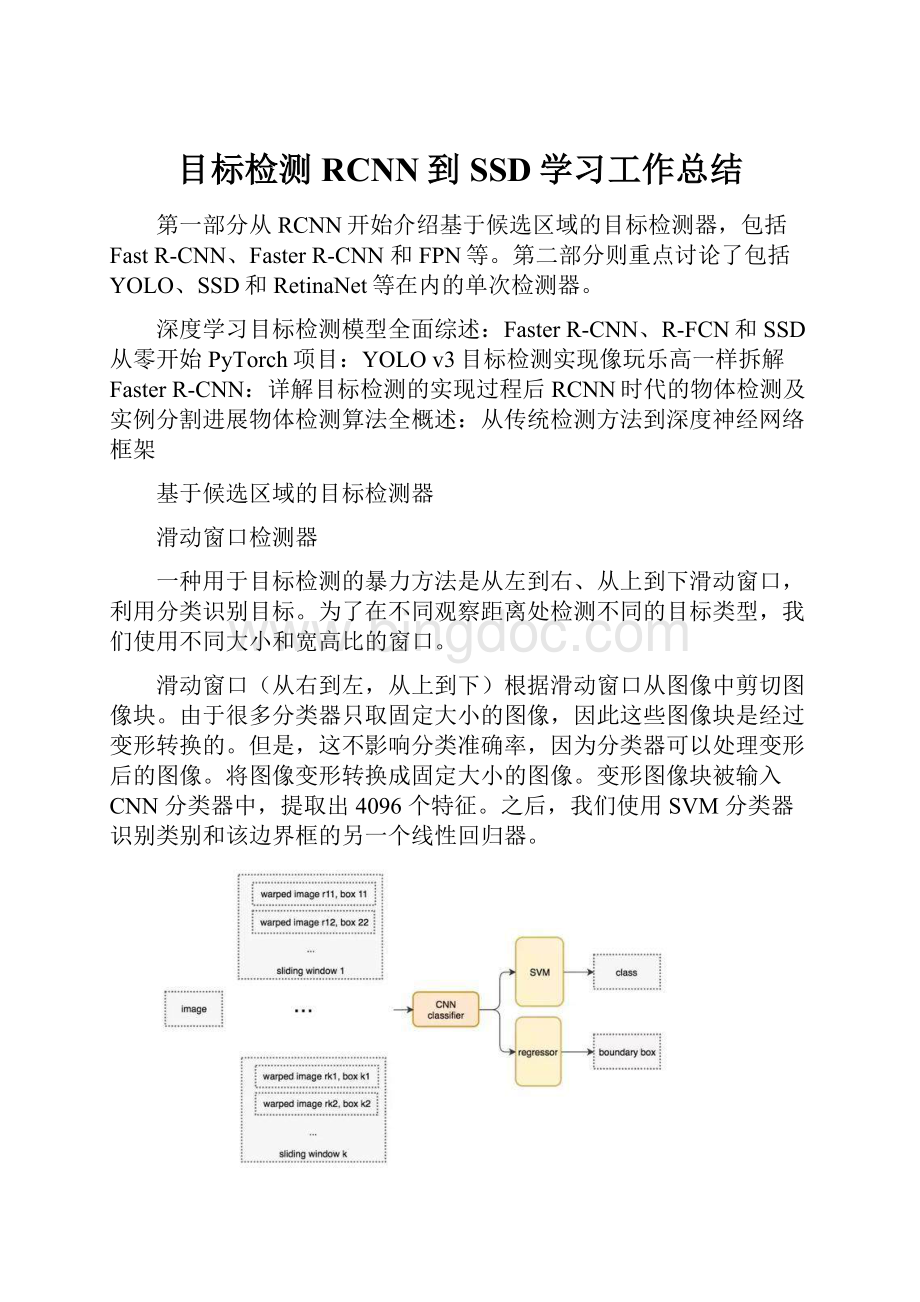
R-CNN
R-CNN利用候选区域方法创建了约2000个ROI。
这些区域被转换为固定大小的图像,并分别馈送到卷积神经网络中。
该网络架构后面会跟几个全连接层,以实现目标分类并提炼边界框。
使用候选区域、CNN、仿射层来定位目标。
以下是R-CNN整个系统的流程图:
通过使用更少且更高质量的ROI,R-CNN要比滑动窗口方法更快速、更准确。
边界框回归器
候选区域方法有非常高的计算复杂度。
为了加速这个过程,通常会使用计算量较少的候选区域选择方法构建ROI,并在后面使用线性回归器(使用全连接层)进一步提炼边界框。
使用回归方法将蓝色的原始边界框提炼为红色的。
FastR-CNN
R-CNN需要非常多的候选区域以提升准确度,但其实有很多区域是彼此重叠的,因此R-CNN的训练和推断速度非常慢。
如果我们有2000个候选区域,且每一个都需要独立地馈送到CNN中,那么对于不同的ROI,我们需要重复提取2000次特征。
此外,CNN中的特征图以一种密集的方式表征空间特征,那么我们能直接使用特征图代替原图来检测目标吗?
直接利用特征图计算ROI。
FastR-CNN使用特征提取器(CNN)先提取整个图像的特征,而不是从头开始对每个图像块提取多次。
然后,我们可以将创建候选区域的方法直接应用到提取到的特征图上。
例如,FastR-CNN选择了VGG16中的卷积层conv5来生成ROI,这些关注区域随后会结合对应的特征图以裁剪为特征图块,并用于目标检测任务中。
我们使用ROI池化将特征图块转换为固定的大小,并馈送到全连接层进行分类和定位。
因为Fast-RCNN不会重复提取特征,因此它能显著地减少处理时间。
将候选区域直接应用于特征图,并使用ROI池化将其转化为固定大小的特征图块。
以下是FastR-CNN的流程图:
在下面的伪代码中,计算量巨大的特征提取过程从For循环中移出来了,因此速度得到显著提升。
FastR-CNN的训练速度是R-CNN的10倍,推断速度是后者的150倍。
FastR-CNN最重要的一点就是包含特征提取器、分类器和边界框回归器在内的整个网络能通过多任务损失函数进行端到端的训练,这种多任务损失即结合了分类损失和定位损失的方法,大大提升了模型准确度。
ROI池化
因为FastR-CNN使用全连接层,所以我们应用ROI池化将不同大小的ROI转换为固定大小。
为简洁起见,我们先将8×
8特征图转换为预定义的2×
2大小。
下图左上角:
特征图。
右上角:
将ROI(蓝色区域)与特征图重叠。
左下角:
将ROI拆分为目标维度。
例如,对于2×
2目标,我们将ROI分割为4个大小相似或相等的部分。
右下角:
找到每个部分的最大值,得到变换后的特征图。
输入特征图(左上),输出特征图(右下),ROI(右上,蓝色框)。
按上述步骤得到一个2×
2的特征图块,可以馈送至分类器和边界框回归器中。
FasterR-CNN
FastR-CNN依赖于外部候选区域方法,如选择性搜索。
但这些算法在CPU上运行且速度很慢。
在测试中,FastR-CNN需要2.3秒来进行预测,其中2秒用于生成2000个ROI。
FasterR-CNN采用与FastR-CNN相同的设计,只是它用内部深层网络代替了候选区域方法。
新的候选区域网络(RPN)在生成ROI时效率更高,并且以每幅图像10毫秒的速度运行。
FasterR-CNN的流程图与FastR-CNN相同
外部候选区域方法代替了内部深层网络
候选区域网络
候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。
它在特征图上滑动一个3×
3的卷积核,以使用卷积网络(如下所示的ZF网络)构建与类别无关的候选区域。
其他深度网络(如VGG或ResNet)可用于更全面的特征提取,但这需要以速度为代价。
ZF网络最后会输出256个值,它们将馈送到两个独立的全连接层,以预测边界框和两个objectness分数,这两个objectness分数度量了边界框是否包含目标。
我们其实可以使用回归器计算单个objectness分数,但为简洁起见,FasterR-CNN使用只有两个类别的分类器:
即带有目标的类别和不带有目标的类别。
对于特征图中的每一个位置,RPN会做k次预测。
因此,RPN将输出4×
k个坐标和每个位置上2×
k个得分。
下图展示了8×
8的特征图,且有一个3×
3的卷积核执行运算,它最后输出8×
8×
3个ROI(其中k=3)。
下图(右)展示了单个位置的3个候选区域。
此处有3种猜想,稍后我们将予以完善。
由于只需要一个正确猜想,因此我们最初的猜想最好涵盖不同的形状和大小。
因此,FasterR-CNN不会创建随机边界框。
相反,它会预测一些与左上角名为「锚点」的参考框相关的偏移量(如x、y)。
我们限制这些偏移量的值,因此我们的猜想仍然类似于锚点。
要对每个位置进行k个预测,我们需要以每个位置为中心的k个锚点。
每个预测与特定锚点相关联,但不同位置共享相同形状的锚点。
这些锚点是精心挑选的,因此它们是多样的,且覆盖具有不同比例和宽高比的现实目标。
这使得我们可以以更好的猜想来指导初始训练,并允许每个预测专门用于特定的形状。
该策略使早期训练更加稳定和简便。
FasterR-CNN使用更多的锚点。
它部署9个锚点框:
3个不同宽高比的3个不同大小的锚点框。
每一个位置使用9个锚点,每个位置会生成2×
9个objectness分数和4×
9个坐标。
R-CNN方法的性能
如下图所示,FasterR-CNN的速度要快得多。
基于区域的全卷积神经网络(R-FCN)
假设我们只有一个特征图用来检测右眼。
那么我们可以使用它定位人脸吗?
应该可以。
因为右眼应该在人脸图像的左上角,所以我们可以利用这一点定位整个人脸。
如果我们还有其他用来检测左眼、鼻子或嘴巴的特征图,那么我们可以将检测结果结合起来,更好地定位人脸。
现在我们回顾一下所有问题。
在FasterR-CNN中,检测器使用了多个全连接层进行预测。
如果有2000个ROI,那么成本非常高。
R-FCN通过减少每个ROI所需的工作量实现加速。
上面基于区域的特征图与ROI是独立的,可以在每个ROI之外单独计算。
剩下的工作就比较简单了,因此R-FCN的速度比FasterR-CNN快。
现在我们来看一下5×
5的特征图M,内部包含一个蓝色方块。
我们将方块平均分成3×
3个区域。
现在,我们在M中创建了一个新的特征图,来检测方块的左上角(TL)。
这个新的特征图如下图(右)所示。
只有黄色的网格单元[2,2]处于激活状态。
在左侧创建一个新的特征图,用于检测目标的左上角
我们将方块分成9个部分,由此创建了9个特征图,每个用来检测对应的目标区域。
这些特征图叫作位置敏感得分图(position-sensitivescoremap),因为每个图检测目标的子区域(计算其得分)。
生成9个得分图
下图中红色虚线矩形是建议的ROI。
我们将其分割成3×
3个区域,并询问每个区域包含目标对应部分的概率是多少。
例如,左上角ROI区域包含左眼的概率。
我们将结果存储成3×
3vote数组,如下图(右)所示。
例如,vote_array[0][0]包含左上角区域是否包含目标对应部分的得分。
将ROI应用到特征图上,输出一个3x3数组。
将得分图和ROI映射到vote数组的过程叫作位置敏感ROI池化(position-sensitiveROI-pool)。
该过程与前面讨论过的ROI池化非常接近。
将ROI的一部分叠加到对应的得分图上,计算V[i][j]。
在计算出位置敏感ROI池化的所有值后,类别得分是其所有元素得分的平均值。
假如我们有C个类别要检测。
我们将其扩展为C+1个类别,这样就为背景(非目标)增加了一个新的类别。
每个类别有3×
3个得分图,因此一共有(C+1)×
3×
3个得分图。
使用每个类别的得分图可以预测出该类别的类别得分。
然后我们对这些得分应用softmax函数,计算出每个类别的概率。
以下是数据流图,在我们的案例中,k=3。
单次目标检测器
单次目标检测器(包括SSD、YOLO、YOLOv2、YOLOv3)
我们将分析FPN以理解多尺度特征图如何提高准确率,特别是小目标的检测,其在单次检测器中的检测效果通常很差。
然后我们将分析Focalloss和RetinaNet,看看它们是如何解决训练过程中的类别不平衡问题的。
单次检测器
FasterR-CNN中,在分类器之后有一个专用的候选区域网络。
FasterR-CNN工作流
基于区域的检测器是很准确的,但需要付出代价。
FasterR-CNN在PASCALVOC2007测试集上每秒处理7帧的图像(7FPS)。
和R-FCN类似,研究者通过减少每个ROI的工作量来精简流程。
作为替代,我们是否需要一个分离的候选区域步骤?
我们可以直接在一个步骤内得到边界框和类别吗?
YOLO
YOLO将全图划分为SXS的格子,每个格子负责中心在该格子的目标检测,采用一次性预测所有格子所含目标的bbox、定位置信度以及所有类别概率向量来将问题一次性解决(one-shot)。
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归boundingbox(边界框)的位置及其所属的类别。
将一幅图像分成SxS个网格(gridcell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
让我们再看一下滑动窗口检测器。
我们可以通过在特征图上滑动窗口来检测目标。
对于不同的目标类型,我们使用不同的窗口类型。
以前的滑动窗口方法的致命错误在于使用窗口作为最终的边界框,这就需要非常多的形状来覆盖大部分目标。
更有效的方法是将窗口当做初始猜想,这样我们就得到了从当前滑动窗口同时预测类别和边界框的检测器。
基于滑动窗口进行预测
这个概念和FasterR-CNN中的锚点很相似。
然而,单次检测器会同时预测边界框和类别。
例如,我们有一个8×
8特征图,并在每个位置做出k个预测,即总共有8×
8×
k个预测结果。
在每个位置,我们有k个锚点(锚点是固定的初始边界框猜想),一个锚点对应一个特定位置。
我们使用相同的锚点形状仔细地选择锚点和每个位置。
使用4个锚点在每个位置做出4个预测。
以下是4个锚点(绿色)和4个对应预测(蓝色),每个预测对应一个特定锚点。
4个预测,每个预测对应一个锚点。
在FasterR-CNN中,我们使用卷积核来做5个参数的预测:
4个参数对应某个锚点的预测边框,1个参数对应objectness置信度得分。
因此3×
3×
D×
5卷积核将特征图从8×
D转换为8×
5。
使用3x3卷积核计算预测。
在单次检测器中,卷积核还预测C个类别概率以执行分类(每个概率对应一个类别)。
因此我们应用一个3×
25卷积核将特征图从8×
25(C=20)。
每个位置做出k个预测,每个预测有25个参数。
单次检测器通常需要在准确率和实时处理速度之间进行权衡。
它们在检测太近距离或太小的目标时容易出现问题。
在下图中,左下角有9个圣诞老人,但某个单次检测器只检测出了5个。
SSD
SSD是使用VGG19网络作为特征提取器(和FasterR-CNN中使用的CNN一样)的单次检测器。
我们在该网络之后添加自定义卷积层(蓝色),并使用卷积核(绿色)执行预测。
YOLO在卷积层后接全连接层,即检测时只利用了最高层featuremaps(包括FasterRCNN也是如此);
而SSD采用了特征金字塔结构进行检测,在多个featuremaps上同时进行softmax分类和位置回归。
SSD使用低层featuremap检测小目标,使用高层featuremap检测大目标
SSD中引入了PriorBox:
预选框+通过softmax分类+boundingboxregression获得真实目标的位置。
同时对类别和位置执行单次预测。
然而,卷积层降低了空间维度和分辨率。
因此上述模型仅可以检测较大的目标。
为了解决该问题,从多个特征图上执行独立的目标检测。
使用多尺度特征图用于检测。
总结
赠送以下资料
总结会讲话稿
在这金秋十月,丹桂飘香的季节,当我们国人还沉浸在“两个奥运,同样精彩”,“神七成功问天”的喜悦中,我们又一次迎来了九月份“6s”总结暨颁奖大会。
首先我代表“6s”小组感谢各位管理和全体同仁在“6s”运动中付出的汗水和努力!
正是有了你们的积极参与,“6s”才得如火如荼,生机盎然,正是有了你们的不懈支持,我们对“6s”运动充满了信心!
9月份参加“6s”考评的有20个单位,以车间为单位的成型一车间在9月份“6s”考评中荣获“团体第一名”,主任陈新华;
以线(组)为单位的成型一车间包边线荣获线(组)第一名,线长罗润生;
成型一车间c线荣获线(组)第二名,线长龙勇;
成型二车间e线荣获线(组)第三名,线长郑权。
我们用最热烈的掌声祝贺以上获奖单位!
最值得一提的是成型一车间和包边线成功卫冕“团体第一名”“线(组)第一名”的殊荣,都说“江山易攻不易守”,在考评分数悬殊不是很大的情况下,能再次登上这光荣的宝座,我们再次把掌声献给他们,谢谢他们对“6s”运动的大力支持。
在9月份,公司进入棉鞋生产高峰期,各位管理人员和员工忙于新品试样与生产,不免对“6s”运动产生疏忽,造成考评成绩整体不是很高,在这里我希望在9月份“6s”运动考评中成绩不是很理想的线(组)、车间,不要气馁,要打起精神,鼓起勇气,不能被一时的落后消磨了你们的锐气,在“6s”面前我们戈美其人是不会低头的!
借这个机会,我觉得还是有必要把“6s”运动的意义跟在座的各位讲讲:
“6s”运动是一项全方位、全过程、全员参与的系统工程,是一项长期的工作,是与生产相辅相成的活动,它既能服务于生产,也能监督生产,想必这一点,各位已体会至深,我们要把“整理、整顿、清扫、清洁、素养、安全”融入到我们工作的每一个细节中。
为了改善和增加作业面积,做到现场无杂物,安全通道畅通,从而提高工作效率,消除管理上的混放、混料等差错事故。
我们就应该彻底地将要与不要的东西归类,并将不要的东西加以处理,需对“留之无用,弃之可惜”的观念予以突破。
为了最终能实现目视管理,把经过整理出来的需要的人、事、物要加以定量、定位、定品。
为了让我们有一个舒适、安全的工作环境,就得要求全员参与,排除隐患,重视预防,彻底地将自己的工作环境四周打扫干净,设备异常时马上维修,以维护人身与财产安全,实现一个零故障,无意外事故发生的工作场所。
千万不要因小失大,对操作人员的操作技能进行训练,要持证上岗,让“勿以善小而不为,勿以恶小而为之”的理念深入到每一位员工的思想中。
为了使现场保持完美和最佳状态,我们需要秉持三个观念:
(1)只有在整齐、干净的工作场所才能产生出高效率、高品质的产品;
(2)6s是一种用心的行为,千万不要只在表面下功夫;
(3)6s是一种随时随地的工作,而不是上下班前后的工作。
最后只有不断努力提高人员的素养,养成严格遵守规章制度的习惯和作风,我们的“6s”活动就能顺利开展,就能坚持下来。
谢谢大家!
 升级会员
升级会员 