正则表达式介绍和例子.docx
《正则表达式介绍和例子.docx》由会员分享,可在线阅读,更多相关《正则表达式介绍和例子.docx(9页珍藏版)》请在冰点文库上搜索。
正则表达式
l含义:
编写字符串处理的程序或网页时,会有查找符合某复杂规则的字符串的需要。
正则表达式就是用于描述这些规则的工具。
它是记录文本规则的代码。
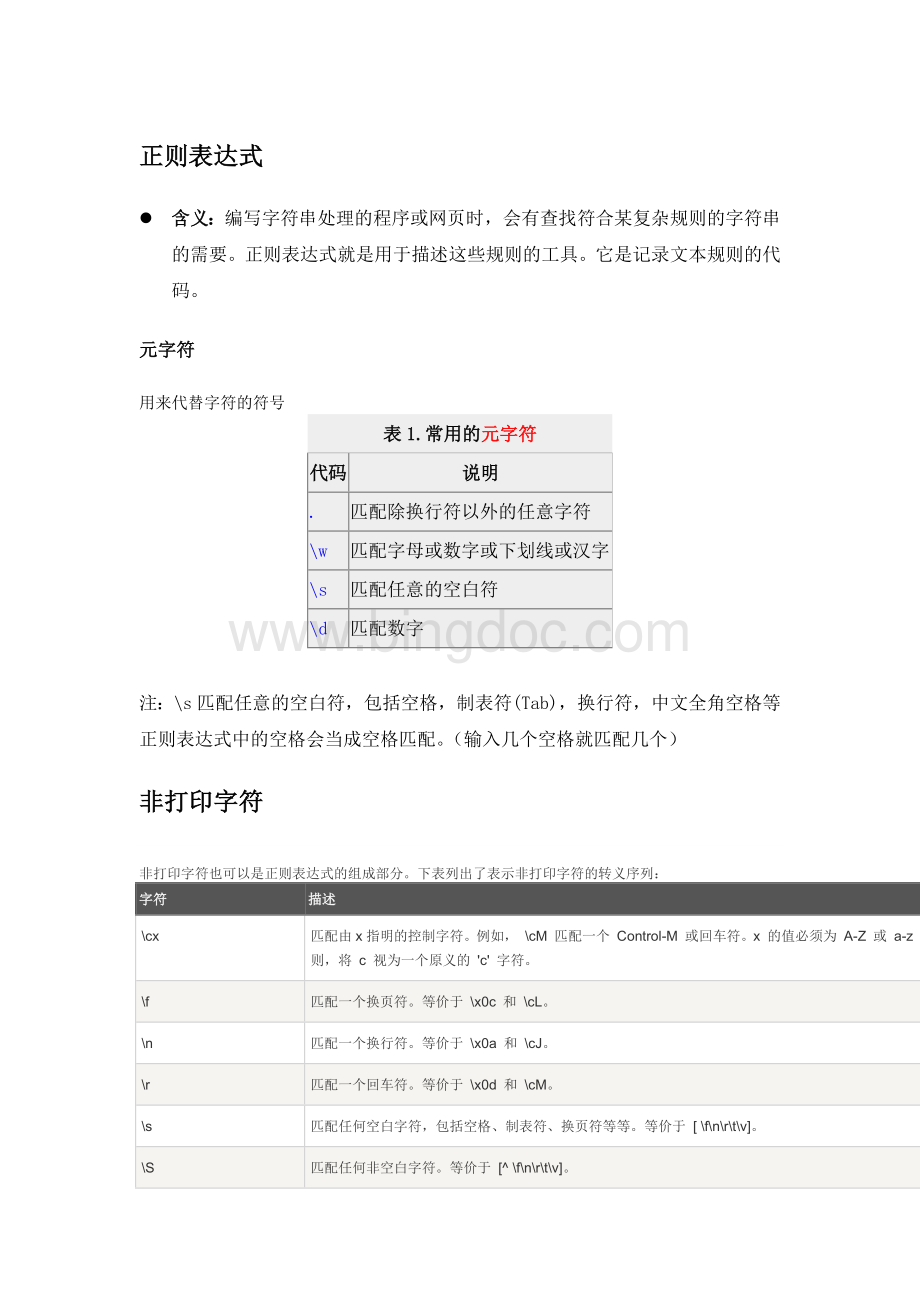
元字符
用来代替字符的符号
表1.常用的元字符
代码
说明
.
匹配除换行符以外的任意字符
\w
匹配字母或数字或下划线或汉字
\s
匹配任意的空白符
\d
匹配数字
注:
\s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等
正则表达式中的空格会当成空格匹配。
(输入几个空格就匹配几个)
非打印字符
非打印字符也可以是正则表达式的组成部分。
下表列出了表示非打印字符的转义序列:
字符
描述
\cx
匹配由x指明的控制字符。
例如,\cM匹配一个Control-M或回车符。
x的值必须为A-Z或a-z之一。
否则,将c视为一个原义的'c'字符。
\f
匹配一个换页符。
等价于\x0c和\cL。
\n
匹配一个换行符。
等价于\x0a和\cJ。
\r
匹配一个回车符。
等价于\x0d和\cM。
\s
匹配任何空白字符,包括空格、制表符、换页符等等。
等价于[\f\n\r\t\v]。
\S
匹配任何非空白字符。
等价于[^\f\n\r\t\v]。
\t
匹配一个制表符。
等价于\x09和\cI。
\v
匹配一个垂直制表符。
等价于\x0b和\cK。
限定符
重复:
表现重复时用的是大括号{}和*+?
,表示范围时用的是中括号[],中括号里面是只选其中一个的组合。
表达分组时用圆括号(),一个圆括号表示一个意思。
表2.常用的限定符
代码/语法
说明
*
重复零次或更多次
+
重复一次或更多次
?
重复零次或一次
{n}
重复n次
{n,}
重复n次或更多次
{n,m}
重复n到m次
l字符类[],用来表示取字符的范围区间,用中括号括起来
[0-9]代表\d
[a-z0-9A-Z]表示\w
l分支条件,用|表示或者的关系。
l贪婪与懒惰、最先开始匹配拥有最高优先权
*、+和?
限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?
就可以实现非贪婪或最小匹配。
.*表示尽可能匹配多的字符
.*?
表示尽可能少的字符
例如:
字符串aabab,用贪婪匹配a.*b得到aabab,用懒惰匹配a.*?
b得到aab和ab
定位符
定位符使您能够将正则表达式固定到行首或行尾。
它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^和$分别指字符串的开始与结束,\b描述单词的前或后边界,\B表示非单词边界。
正则表达式的限定符有:
字符
描述
^
匹配输入字符串开始的位置。
如果设置了RegExp对象的Multiline属性,^还会与\n或\r之后的位置匹配。
$
匹配输入字符串结尾的位置。
如果设置了RegExp对象的Multiline属性,$还会与\n或\r之前的位置匹配。
\b
匹配一个字边界,即字与空格间的位置。
\B
非字边界匹配。
子表达式分组获取()
l分组,用()把子表达式括起来,给一个组号,后面可以再用
l后向引用,用()定义的分组,可以给它定一个组名,在后面加以利用。
用(?
\w+)或者(?
’Word’\w+)定义\w+组名为Word,利用方式为\k
表4.常用分组语法
分类
代码/语法
说明
捕获
(exp)
匹配exp,并捕获文本到自动命名的组里
(?
exp)
匹配exp,并捕获文本到名称为name的组里,也可以写成(?
'name'exp)
非捕获
(?
:
exp)
匹配exp,不捕获匹配的文本,也不给此分组分配组号
零宽断言
(?
=exp)
匹配exp前面的位置
(?
<=exp)
匹配exp后面的位置
(?
!
exp)
匹配后面跟的不是exp的位置
(?
exp)
匹配前面不是exp的位置
注释
(?
#comment)
这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读
捕获
从下面的例子中可以看到,根据正则表达式,只捕获了括号内的东西到组中,第一个括号前面^\D*匹配到的东西被忽略了。
零宽度断言
(?
=exp)用法:
\b\w+(?
=ing)\b,匹配以ing结尾的单词的前面部分,如查找I’msinginganddancing,会匹配sing和danc
(?
<=exp)用法:
(?
<=rea)\w+\b,匹配以rea开头的单词的后面部分,如查找readingabook,会匹配ding
注释:
(?
#comment)
例如:
2[0-4]\d(?
#200-249)|25[0-5](?
#250-255)|[01]?
\d\d?
(?
#0-199)
反义
l反义,找完全相反的内容。
注意这里使用的都是大写
表3.常用的反义代码
代码/语法
说明
\W
匹配任意不是字母,数字,下划线,汉字的字符(剩下符号等)
\S
匹配任意不是空白符的字符
\D
匹配任意非数字的字符
\B
匹配不是单词开头或结束的位置
[^x]
匹配除了x以外的任意字符
[^aeiou]
匹配除了aeiou这几个字母以外的任意字符
平衡组/递归匹配
(?
'group')把捕获的内容命名为group,并压入堆栈(Stack)
(?
'-group')从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败
(?
(group)yes|no)如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分
(?
!
)零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败
<[^<>]*(((?
'Open'<)[^<>]*)+((?
'-Open'>)[^<>]*)+)*(?
(Open)(?
!
))>
可以从xxaa>yy中找到aa>
]*>[^<>]*(((?
'Open']*>)[^<>]*)+((?
'-Open'
 升级会员
升级会员 